Humans observe the world through a combination of different modalities, like vision, hearing, and our understanding of language. Machines, on the other hand, interpret the world through data that algorithms can process.
So, when a machine “sees” a photo, it must encode that photo into data it can use to perform a task like image classification. This process becomes more complicated when inputs come in multiple formats, like videos, audio clips, and images.
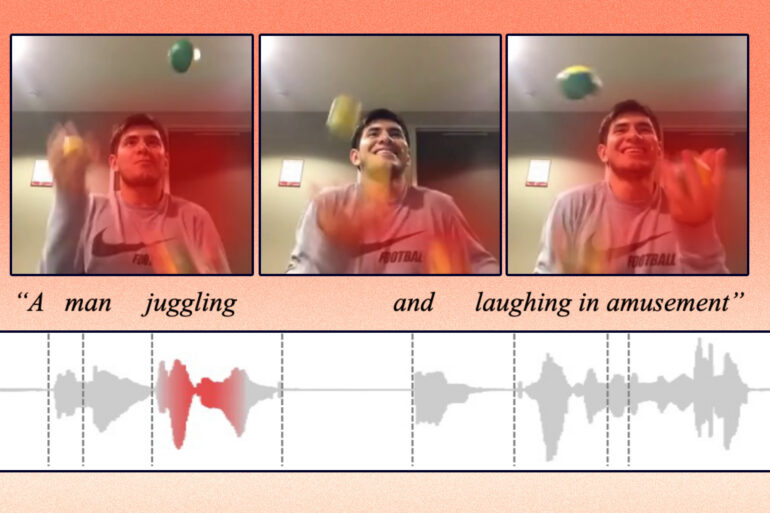
“The main challenge here is, how can a machine align those different modalities? As humans, this is easy for us. We see a car and then hear the sound of a car driving by, and we know these are the same thing. But for machine learning, it is not that straightforward,” says Alexander Liu, a graduate student in the Computer Science and Artificial Intelligence Laboratory (CSAIL) and first author of a paper tackling this problem.
Liu and his collaborators developed an artificial intelligence technique that learns to represent data in a way that captures concepts which are shared between visual and audio modalities. For instance, their method can learn that the action of a baby crying in a video is related to the spoken word “crying” in an audio clip.
Using this knowledge, their machine-learning model can identify where a certain action is taking place in a video and label it.

It performs better than other machine-learning methods at cross-modal retrieval tasks, which involve finding a piece of data, like a video, that matches a user’s query given in another form, like spoken language. Their model also makes it easier for users to see why the machine thinks the video it

