Cornell researchers developed a more equitable method for choosing top candidates from a large applicant pool in cases where insufficient information makes it hard to choose.
While humans still make many high-stakes decisions—like who should get a job, admission to college or a spot in a clinical trial—artificial intelligence (AI) models are increasingly used to narrow down the applicants into a manageable shortlist. In a new study, researchers in the Cornell Ann S. Bowers College of Computing and Information Science found that conventional ranking methods become unfair if the model knows more about some candidates than others—and this disparity often affects people from minority groups.
Conventional methods frequently give these candidates a low ranking, not because the algorithm is sure they are unqualified, but merely because it lacks information. This issue is called “disparate uncertainty.” In these situations, far fewer of the qualified applicants in the group with less data ever advance to the shortlist for human review.
“The phenomenon of disparate uncertainty is quite widespread, and a source of unfairness, particularly in rankings,” said Richa Rastogi, a doctoral student in the field of computer science. “If none of this other group even gets shortlisted, there is no way the human decision-makers can ever realize they are qualified.”
Rastogi presented this work, “Fairness in Ranking under Disparate Uncertainty,” at the ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO’24), Oct. 29 in San Luis Potosí, Mexico. The paper is published on the arXiv preprint server.
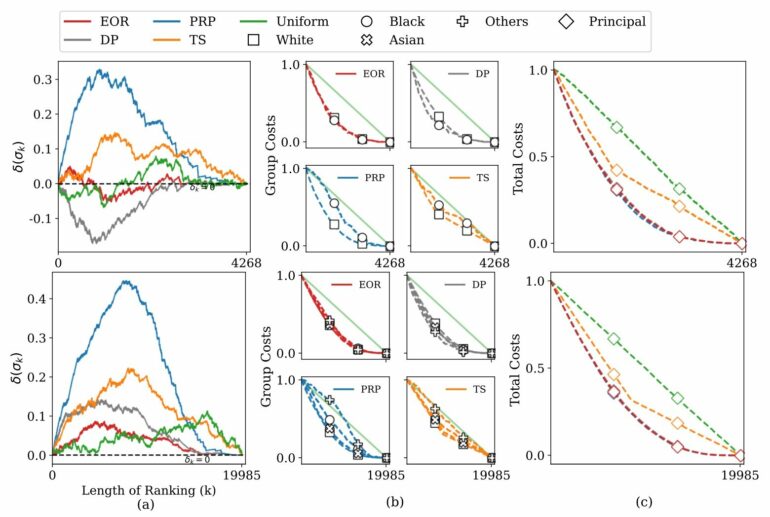
In the new paper, Rastogi and senior author Thorsten Joachims, the Jacob Gould Schurman Professor of computer science and information science, figured out a way to quantify the amount of unfairness that occurs when the ranking algorithm passes over qualified people in the low-information group. These individuals bear the majority of the unfairness burden compared to the high-information group, whose members are more likely to make it onto the shortlist.
One way to even out the burden between the groups is to randomly select from all the applicants—essentially turning the process into a lottery. But a random lottery is inefficient for selecting the qualified candidates from a large pool, Rastogi said.
Instead, she developed a ranking algorithm called Equal-Opportunity Ranking (EOR), which spreads out the unfairness burden more equally between the two groups, while still successfully selecting qualified individuals. EOR works by shortlisting an equal fraction of qualified candidates from both groups.
“We showed the EOR algorithm brings qualified candidates to the top, and at the same time is equivalent to a lottery among qualified candidates across all the groups,” Joachims said. “The surprising thing is that EOR can do this despite not accurately knowing who is qualified.”
Using different real-world datasets, Rastogi showed EOR was more fair than existing ranking algorithms in cases with disparate uncertainty.
In one example, she simulated the problem of finding candidates that may be eligible for a certain benefit. Using U.S. Census information from more than 125,000 people, EOR was able to select individuals of a specific income level based on demographic and employment data in a way that was more fair than other ranking methods, even though the underlying AI model was biased for some racial groups.
EOR also has another application: auditing the fairness of search results. Rastogi used it to evaluate whether Amazon is likely listing its own branded products above higher-ranked items from other sellers in its search results—an accusation made previously by investigative journalists.
The researchers used a publicly available dataset of Amazon shopping searches created by journalists and a sample model from Amazon that ranks recommended products on the site. They found that Amazon sometimes ranks its own products higher than if it had used the EOR method.

They caution, however, that this isn’t conclusive proof of unfairness, since they don’t have access to the actual model Amazon uses to produce its product recommendations.
More information:
Richa Rastogi et al, Fairness in Ranking under Disparate Uncertainty, arXiv (2023). DOI: 10.48550/arxiv.2309.01610
Provided by
Cornell University
Citation:
New algorithm picks fairer shortlist when applicants abound (2024, October 30)

