A key question in a number of court cases is whether a speaker on an audio recording is a particular known speaker, for example, whether a speaker on a recording of an intercepted telephone call is the defendant.
In most English-speaking countries, expert testimony is only admissible in a court of law if it will potentially assist the judge or the jury to make a decision. If the judge or the jury’s speaker identification were equally accurate or more accurate than a forensic scientist’s forensic voice comparison, then the forensic-voice-comparison testimony would not be admissible.
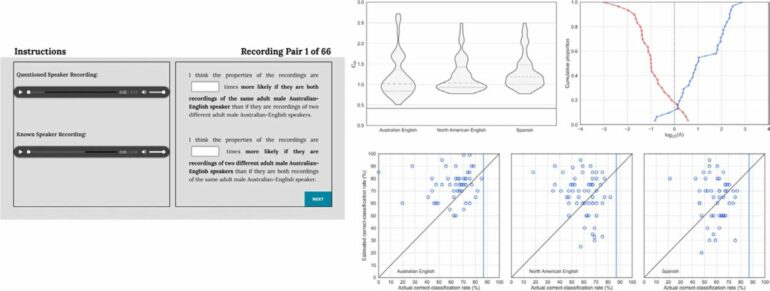
In a research paper published in the journal Forensic Science International, a multidisciplinary international team of researchers has reported the first set of results from a comprehensive study that compares the accuracy of speaker-identification by individual listeners (like judges or jury members) with the accuracy of a forensic-voice-comparison system that is based on state-of-the-art automatic-speaker-recognition technology, and that does so using recordings that reflect the conditions of an actual case.
The questioned-speaker recording was of a telephone call with background office noise, and the known-speaker recording was of a police interview conducted in echoey room with background ventilation-system noise.
The forensic-voice-comparison system performed better than all the 226 listeners who were tested.
The research team was made up of forensic data scientists, legal scholars, experimental psychologists, and phoneticians, based in the UK, Australia, and Chile.
Corresponding author Dr Geoffrey Stewart Morrison, director of the Forensic Data Science Laboratory at Aston University, said, “A few years ago, when I was testifying in a court case, I was asked by a lawyer why the judge couldn’t just listen to the recordings and make a decision. Wouldn’t the judge do better than the forensic-voice-comparison system that I had used?”
“That was the spark that lead to us conducting this research. I was expecting our forensic-voice-comparison system to perform better than most of the listeners, but I was surprized when it actually performed better than all of them. I’m happy that we now have such a clear answer to the question asked by the lawyer.”
Contributing author Dr. Kristy A Martire, School of Psychology at the University of New South Wales, said, “Past experiences where we have successfully recognized familiar speakers, such as family members or friends, can lead us to believe that we are better at identifying unfamiliar voices than we really are. This study shows that whatever ability a listener may have in recognizing familiar speakers, their ability to identify unfamiliar speakers is unlikely to be better than a forensic-voice-comparison system.”
Contributing author Professor Gary Edmond, School of Law at the University of New South Wales, said, “Unequivocal scientific findings are that identification of unfamiliar speakers by listeners is unexpectedly difficult and much more error-prone than judges and others have appreciated. We should not encourage or enable nonexperts, including judges and jurors, to engage in unduly error-prone speaker identification. Instead, we should seek the services of real experts: specialist forensic scientists who employ empirically validated and demonstrably reliable forensic-voice-comparison systems.”

More information:
Nabanita Basu et al, Speaker identification in courtroom contexts—Part I: Individual listeners compared to forensic voice comparison based on automatic-speaker-recognition technology, Forensic Science International (2022). DOI: 10.1016/j.forsciint.2022.111499
Citation:
Automatic speaker recognition technology outperforms human listeners in the courtroom (2022, November 7)

