Researchers at Carnegie Mellon University and the University of Toronto have developed a new k-mer sketching metagenomic profiler, called sylph, that allows scientists to analyze genomic data more quickly and precisely than other profilers.
The related paper is published in the journal Nature Biotechnology.
“Sequencing is getting better, which is great because it means we have more data to work with,” said Yun William Yu, an assistant professor in CMU’s Ray and Stephanie Lane Computational Biology Department in the School of Computer Science. “But that also means we have more data to check, which can take more time.”
For example, when profiling a sample from the human gut to determine the bacteria present, other methods read the sequenced genomic data; match it to specific bacteria, such as E. coli or C. diff; and then determine the proportion of these bacteria in the sample.
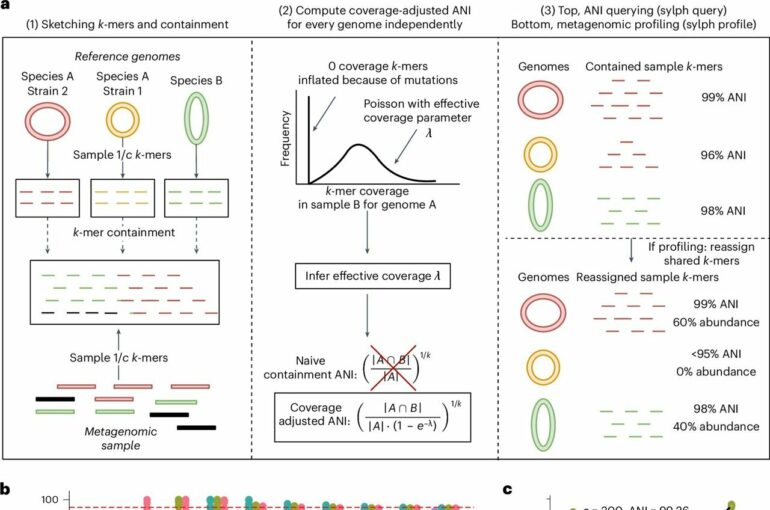
Sylph reverses the process by comparing known bacteria to the sample. The method breaks bacterial genomes into smaller subsamples, called k-mers, which are then compared to the initial sample. If a certain proportion of one subsample is found, sylph can conclude that bacteria is present.
Yu and Jim Shaw, a postdoctoral fellow at Harvard Medical School and Dana-Farber Cancer Institute who worked on this method with Yu while at the University of Toronto, found that sylph uses fewer computing resources and runs faster than other profilers.
“Sylph helps with computational workflow for these kinds of problems,” Yu said. “It also means we can scale to much larger datasets in computational biology research. As we get more and more sequencing data, many of these other tools scale worse. Obviously, as we get more data we have to read more data and sylph also slows down. But our tool will stay faster for a longer time.”
Along with speed, researchers found that sylph is more precise than other profilers. Sylph’s innovation, researchers wrote, “is a statistical model based on zero-inflated Poisson statistics to debias containment average nucleotide identity (ANI) under low coverage, solving the low-abundance ANI calculation problem.”
The model’s formula can be adjusted by proportions, allowing it to detect rare genomes present in the sample.
Yu said he plans to adapt some aspects of sylph into his future work to improve computational analysis tools.

More information:
Jim Shaw et al, Rapid species-level metagenome profiling and containment estimation with sylph, Nature Biotechnology (2024). DOI: 10.1038/s41587-024-02412-y
Provided by
Carnegie Mellon University
Citation:
Metagenomic profiling method with enhanced precision uses fewer computing resources (2024, November 13)

