The voice assistant speaker box you may have purchased during last week’s Black Friday sale is a client-side device that links you perpetually to Apple’s or Amazon’s massive cloud service. It’s through this service that algorithms from “distributed” servers, albeit in centralized facilities, determine the intent of your commands through the phonemes they ascertain. Here, algorithms purporting to be the world’s finest examples of artificial intelligence in action, including decision trees, natural language evaluators, and machine learning arrays, consume considerable wattage every time you ask them to turn down the lights so you can save energy.
It is one of the grander examples of well-intentioned inefficiency in the tale of modern technology: We’ve made our 15-amp light switches and 20-amp volume knobs “smart,” then distributed the smarts to servers hosted in 60 MW data centers. Like carbon fuel-powered locomotion, this probably won’t stand for long.
At one point, this system may be replaced by a self-contained device that determines your intent without connecting to anyone’s hyperscale data forest. It would consume far less energy — certainly no more than a human being produces for herself over the course of a day. It would have its own sense of observation, reason, and intuition — or at least, one whose results are satisfactory enough that it doesn’t really matter whether its sensibilities are artificial or real. What’s the difference, really?
The problem at hand is this: how to learn how to learn. That is, if a box that you take home with you is expected to learn your intentions, your motivations, your quirks over time, then can the process of seeding such a device with the capacity to learn its own individualized, specialized, custom algorithm, be imprinted upon such a device before it emerges from the factory? Certainly that’s a more realistic image for us to conjure up, than such a device being “born” and then “learning” from experience, like one of us. If not more realistic, than at least more comfortable.

“Is there ultimately no difference… ?”
If we have been right in our analysis of mind, the ultimate data of psychology are only sensations and images and their relations. Beliefs, desires, volitions, and so on, appeared to us to be complex phenomena consisting of sensations and images variously interrelated. Thus (apart from certain relations) the occurrences which seem most distinctively mental, and furthest removed from physics, are, like physical objects, constructed or inferred, not part of the original stock of data in the perfected science. From both ends, therefore, the difference between physical and psychological data is diminished. Is there ultimately no difference, or do images remain as irreducibly and exclusively psychological? In view of the causal definition of the difference between images and sensations, this brings us to a new question, namely: Are the causal laws of psychology different from those of any other science, or are they really physiological?
-Bertrand Russell
The Analysis of Mind, 1921
What fascinated Bertrand Russell a century ago is what fascinates neuromorphic engineers today: the study of whether the mind is so much a machine that a device that mimics the function of a brain gains some power attributed to the mind. We think of a “mind” as a reasoning, living thing. Russell pursued this idea, not to its conclusion but just long enough to give us a sense of the right direction: The moment we understand “mind” well enough to reproduce its function artificially, does it cease to be “mind” by our own definition?
The first chess-playing consumer devices were marketed by retailers such as Radio Shack as “electronic minds.” If you’ve ever played chess against one of these devices, against an early program such as Sargon, or more recently against an app, you have toyed with one of the earliest and most basic forms of AI: the decision tree. Liberal use of the word “decision” ends up making this branch sound way too grandiose; in practice, it’s extremely simple, and it has zero to do with the shape or form of the brain.
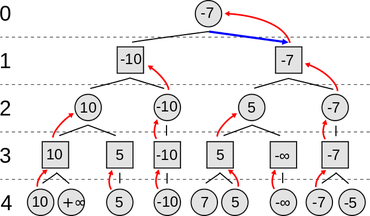
Diagram of a minimax decision tree by Nuno Nogueira. Released through Wikimedia Commons.
Essentially, a decision tree algorithm applies numeric values to assessed possibilities. A chess program evaluates all the possibilities it can find, for moves and counter-moves and counter-counter-moves well into the future, and chooses the move with the best assessed value. One chess program may distinguish itself from the others through the value points it attributes to the exposure or capture of an important piece, or the closure of an important line of defense.
The ability to condense these evaluations into automated response patterns may constitute what some would call, at least rudimentarily, a “strategy.” Adapting that strategy to changing circumstances is what many researchers would call learning. Google’s DeepMind system is one example of a research project that applies purely mathematical logic to the task of machine learning, including this example involving modeling responses to multiple patients’ heart and lung behavior.
We have a tendency to define a “computer” as unquestionably digital, and everything that performs a computing task as a digital component. As neuromorphic science extends itself into the architecture of computing hardware, such as processors, scientists have already realized there are elements of neuromorphology that, like quantum computing, cannot be modeled digitally. Randomness, or otherwise inexplicable phenomena, are part of their modus operandi.

A digital computer that electronically represents all logic in the form of binary interactions, is said to have a von Neumann architecture, after the man credited with bringing it about. The one key behavior that essentially disqualifies a von Neumann machine from completely mimicking an organic or a subatomic entity, is the very factor that makes it so dependable in accounting: its determinism. The whole point of a digital computer program is to determine how the machine must function, given a specific set of inputs. All digital computer programs are either deterministic or they’re faulty.
The brain of a human being, or any animal thus far studied, is not a deterministic organism. We know that neurons are the principal components of memory, though we don’t really know — in many cases, we’re just guessing — how experiences and sensory inputs map themselves to these neurons. Scientists have observed, though, that the functions through which neurons “fire” (display peak electrical charges) are probabilistic. That’s to say, the likelihood that any one neuron will fire, given the same inputs (assuming they could be re-created), is a value less than 100%.
Power spike
Neither neurologists nor programmers are entirely certain why a human brain can so easily learn to recognize letters when they have so many different typefaces, or to recognize words when people’s voices are so distinct. If you think of the brain as though it were a muscle, it could be stress that improves and strengthens it. Indeed, intellect (the phenomena arising from the mind’s ability to reason) could be interpreted as a product of the brain adapting to the information its senses infer from the world around it, by literally building new physical material to accommodate it. Neurologists refer to this adaptation as plasticity, and this is one of the phenomena that neuromorphic engineers are hoping to simulate.
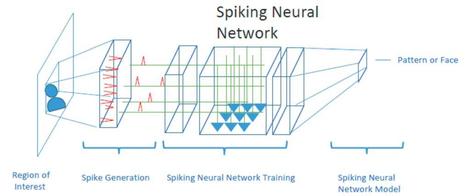
Diagram by Alish Dipani, released through Intel Developer Mesh.
A spiking neural network (SNN) is an effort to achieve better plasticity through algorithms. In the biological brain, each neuron is connected to a variety of inputs. Some inputs produce excitation in the neuron, while others inhibit it — like the positive and negative weights in a typical artificial neural net.
By contrast, an SNN is a biomimetic platform. It endeavors to use physical means, rather than digital, to simulate the biochemical processes of the brain. With an SNN, upon reaching a certain threshold state described by a variable (or perhaps with a function), the neuron’s state “fires,” generating a spike that is registered as electrical output. The purpose of an SNN model is to draw inferences from these spikes — to see if an image or a data pattern triggers a memory.
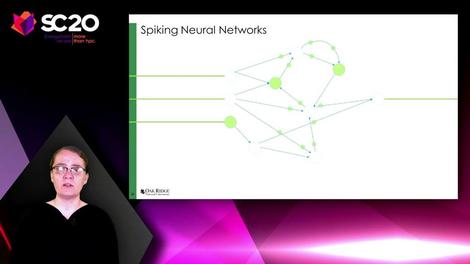
“Spiking neural networks look a little bit different from the traditional artificial neural network cartoon,” explained Dr. Catherine Schuman, a research scientist at Oak Ridge National Laboratory, speaking during the recent Supercomputing 2020 virtual conference. “The first key feature is that spiking neural networks have a notion of time in how they operate. . . That means the synapses can have a delay, where it takes time for information to travel from one side of the synapse to the other. Neurons can also have a notion of delay and time in the way that they operate as well.”

Gone is the layered, structured organization of the weights-and-measures system. In its place is a model that looks less than the ideal state of my father’s fishing tackle box, than what it typically did look like. In this frame from a video depicting an actual SRNN, the yellow spots (clumped together in a straight line) represent input neurons, the red spots (almost masked on the right) are the outputs, and then instead of a hidden layer, the teal spots are the tangled web of interrelated events.
The synapses (the lines connecting neurons) are divided into excitatory and inhibitory varieties. These may be analogous to positive and negative weights, respectively, in a more conventional model, adjusting the probabilities that the teal neurons will “fire.” The white dots, which pop up different places, are spikes.
“For spiking recurrent neural networks,” said Schuman, “you can have any two neurons connected to each other by synapse, or even multiple synapses. Spiking neural networks also receive input over time, in the form of spikes, and they produce output in the form of spikes over time. And you can encode numerical information as spikes, by putting more spikes in for larger values, or encoding them with the rate of spikes as they arrive, or even encoding them with the time at which the spikes arrive.”
Why? “Spikes” are representative of stimuli, either to a brain or from a brain. Memories, in the context of how you and I perceive remembered events, are spikes produced through electrical impulses through neurons. A typical digital neural net works like a gumball machine: You fill up the database with memories, insert an image, let it imprint upon the remembered patterns, and it spits out whatever memory gets triggered. Spike in, spike out. By contrast, with an SNN, a memory is triggered by whatever chance interaction may take place.
Schuman offered this example: determining the shortest path between obstructed points on a map. “The conversion into a spiking neural network is very natural,” she said. “You take a graph, you turn every node into a neuron, you turn every edge into a synapse, and then you do some sort of computation on that. So if you have a weighted graph, you can take the distances on the edges and covert them into delays on the synapses. Then you can have spikes travel throughout the network, in order to give you single-source, shortest paths.”
Notice how Dr. Schuman refers to delays as symbols here. This is because, with SNN, time actually serves as a function.
In a completely static system, where information states are entirely binary, time is the enemy, and the passage of time is considered latency. An SNN realizes, however, that a spike is not a binary state but a function, which may be plotted on an heuristic chart. The X-axis of that chart represents time, and the Y-axis amplitude. The shape the spike makes on this chart is, in and of itself, informational. Time is actually required. It’s one dimension in which information may actually be stored. In a completely counter-intuitive fashion to anything human beings have ever engineered before, the amount of information conveyed by the shape of a spike rises exponentially as the amount of time rises linearly. Indeed, as engineers have discovered [PDF], the act of trying to “flatten” inputs and outputs for an SNN to one-dimensional arrays, consumes more time than is saved by simply letting spikes take their own time.
The result is something of an unexpected revelation, more of a discovery than an outright invention: event-driven computation. You may already be familiar with the old concept of “event-driven architecture,” which is an asynchronous programming model used in today’s Web applications. A request is placed by one module or code element, but it doesn’t hold still or remain dormant while awaiting a response to that request. Event-driven computation (which is so new, it has yet to be given its own abbreviation) has a few conceptual similarities, but with a fundamentally different outcome. When a trained SNN is given a set of inputs and exactly the right amount of time, it “fires” spikes toward its outputs at the same time interval. Not just the spikes themselves, but the patterns they form along each output, represent information.
The upshot of all this is, for now, bewildering: An SNN may be capable of drawing inferences about its inputs for which no one intended for it to have been trained, producing spikes for reasons beyond the obvious. In other words, it could fulfill a program that no one explicitly wrote. Think of this as artificial intuition — the ability to perceive something, and infer meaning from that perception, without an obvious catalyst.
American gladiators
You can imagine a world of academic, and even commercial, computing where SNNs are prized champions for their ability to draw inferences in particular categories, or perhaps generally. Such a network algorithm could not only be trained but cultivated, nurtured, raised. To the extent that two or more algorithms may be called upon to help produce a new one, SNNs could be bred.
Oak Ridge even has a delightfully euphemistic algorithm for this: EONS (Evolutionary Optimization for Neuromorphic Systems).
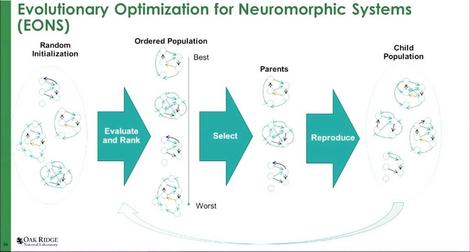
Dr. Schuman and her Oak Ridge and University of Tennessee colleagues presented an updated version of this concept in a white paper published this year [PDF]. In it, the team explains that an SNN is something that needs to be trained to become functional. Programming only goes so far as to make the system ready to be trained. At this point in the technique’s development, there is no standard methodology for explicitly training an SNN. And because the training characteristics change so broadly with each task, the type of standardization that normally leads to automation, may be difficult to attain.
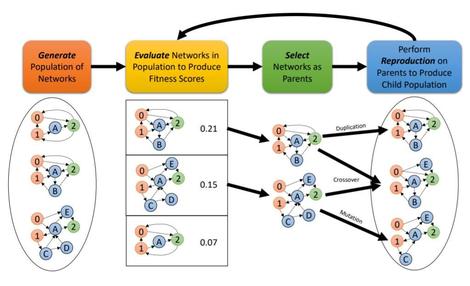
Overview of the Evolutionary Optimization for Neuromorphic Systems training approach.
US Dept. of Energy
The solution the Tennessee team proposes is literally to throw solutions at the wall and let Darwin sort it out. Quite literally, the EONS approach would have trainers begin with populations of possible algorithmic SNN solutions to a problem, some of which will be purely random. Population sizes here could number into the hundreds of thousands. Methods not unlike decision trees will simulate each algorithm in action, and evaluate its effectiveness at attaining something approaching a solution. Leading scorers will be pitted against one another in what, once again literally, are called tournaments. The fittest algorithms are the ones that survive.

“Now, at the beginning, when they’re randomly initialized,” described Dr. Schuman, “they’re not all going to be very good. In fact, they’re mostly going to be pretty bad. But some are going to be less bad than others, allowing us to establish this ranking.”
As radio engineers discovered to their amazement long ago, the best way to separate signal from noise is to have a whole lot of reliably random noise.
Also: What is quantum computing today? The how, why, and when of a paradigm shift
To pare the process down somewhat, the survivors are banded together to form a kind of DNA pool. The best and brightest of these survivors are then preferentially selected. Then they produce offspring, utilizing methods of duplication, crossover, and mutation inspired by genetic science. The results are SNNs capable of what the Tennessee team is unafraid to call reproduction.
“From there on out, we’re going to repeat the evaluation and ranking, selection, and reproduction processes with our child populations,” she continued, “and we’re going to iterate until we get a certain number of generations, or we reach a certain desired performance level.”
Should neuromorphic computers ever join supercomputers, and perhaps also quantum computers, in the modeling and simulation of real-world situations, creating SNNs for customers must become a profitable business. It should not be so wild a dream to imagine a commercial enterprise for developing neuromorphic programs through — let’s call it what it is — selective breeding.
It wasn’t so wild an idea that Dr. Schuman would dismiss it out-of-hand.
“We have the software — we’re close, right now,” she responded. Traditional supercomputers are now being called upon to execute time-tested algorithms, she said, to select the right SNN for a particular task.
Responding to our question, and probably to her great credit, Schuman did make an effort to scale the idea down. For instance, she suggested that a commercial neuromorphic system could be produced in a portable form factor. In that case, it would need to be factory-trained using a standard procedure, although it could be pre-seeded with the ability to evolve itself down the road.
“I think one of the most compelling uses of neuromorphic in deployment is continued adaptations, once you’re actually pushed out in the field,” she told ZDNet. “Like real-time learning that might happen on the chip, maybe at a smaller scale, so you’re not just ‘fully learning’ on the chip, doing some sort of pre-training and then deploying. I think that’s a really compelling use case that we are still studying, still trying to understand what that’s going to look like, and what the hardware’s going to look like, to be able to enable that. So from that perspective, that’s a little ways off.”
The unknown factor at this point, Dr. Schuman told ZDNet, is whether it will be feasible to continually adapt an SNN in software, and deploy that network to neuromorphic hardware (not unlike deploying a container to a Kubernetes cluster) without first having to adapt the hardware. “Whether or not you can build the right hardware for your application is still an open question,” she said, “with the fabrication technologies we have today.”
Anyone who thought Bertrand Russell postulated that mental processes could some day be reduced to calculations, never read through to the end of his treatise. “The question whether it is possible to obtain precise causal laws in which the causes are psychological, not material,” he wrote, “is one of detailed investigation.” Russell continued:
I have done what I could to make clear the nature of the question, but I do not believe that it is possible as yet to answer it with any confidence. It seems to be by no means an insoluble question, and we may hope that science will be able to produce sufficient grounds for regarding one answer as much more probable than the other. But for the moment I do not see how we can come to a decision.
It’s the open questions whose answers carry the greatest weight.
[Portions of this article appeared in an earlier ZDNet Executive Guide on neuromorphic computing, and were updated to reflect the current state of the science.]
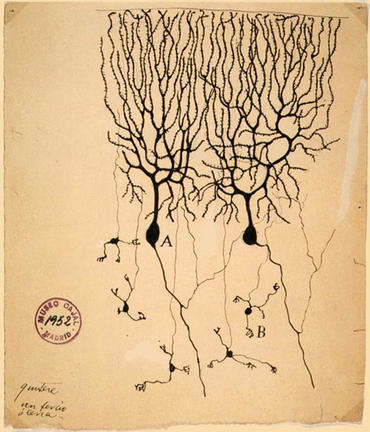
The backdrops for this edition of ZDNet Scale were inspired by the drawings of Santiago Ramon y Cajal, who discovered the guiding principles for the operation of neurons in the brain. He first published his discoveries accompanied by original ink drawings, leveraging his skills as an artist — using, many would say today, both sides of his brain. For this, Cajal was awarded the Nobel Prize in 1906. The example at left is in the collection of Instituto Cajal in Madrid, and this photo in the public domain.

