
Cerebras added to its previously annouced CS-2 AI computer with a new switch product, the SwarmX, that does routing but also calculations, and a memory computer containing 2.4 petabytes of DRAM and NAND, called MemoryX.
Cerebras Systems
Artificial intelligence in its deep learning form is producing neural networks that will have trillions and trillions of neural weights, or parameters, and the increasing scale presents special problems for the hardware and software used to develop such neural networks.
“In two years, models got a thousand times bigger and they required a thousand times more compute,” says Andrew Feldman, co-founder and CEO of AI system maker Cerebras Systems, summing up the recent history of neural nets in an interview with ZDNet via Zoom.
“That is a tough trajectory,” says Feldman.
Feldman’s company this week is unveiling new computers at the annual Hot Chips computer chip conference for advanced computing. The conference is being held virtually this year. Cerebras issued a press release announcing the new computers.
Cerebras, which competes with the AI leader, Nvidia, and with other AI startups, such as Graphcore and SambaNova Systems, aims to lead in performance when training those increasingly large networks. Training is the phase where a neural net program is developed by subjecting it to large amounts of data and tuning the neural net weights until they produce the highest accuracy possible.
Also: ‘We can solve this problem in an amount of time that no number of GPUs or CPUs can achieve,’ startup Cerebras tells supercomputing conference
It’s no secret that neural networks have been steadily growing in size. In the past year, what had been the world’s largest neural net as measured by neural weights, OpenAI’s GPT-3 natural language processing program, with 175 billion weights, was eclipsed by Google’s 1.6-trillion-parameter model, the Switch Transformer.
Such huge models run into issues because they stretch beyond the bounds of a single computer system. The memory of single GPU, on the order of 16 gigabytes, is overwhelmed by potentially hundreds of terabytes of memory required for a model such as GPT-3. Hence, clustering of systems becomes crucial.
And how to cluster becomes the crucial issue, because each machine must be kept busy or else the utilization drops. For example, this year, Nvidia, Stanford and Microsoft created a version of GPT-3 with one trillion parameters, and they stretched it across 3,072 GPUs. But the utilization, meaning, the number of operations per second, was only 52% of the peak operations that the machines theoretically should be capable of.
Hence, the problem Feldman and Cerebras set about to solve is to handle larger and larger networks in a way that will get better utilization of every computing element, and thereby lead to better performance, and by extension, better energy usage.
The new computers include three parts that interoperate. One is an update of the company’s computer that contains its Wafer-Scale Engine or WSE, chip, the largest chip ever made. That system is called the CS-2. Both WSE2 and CS-2 were introduced in April.
Also: Cerebras continues ‘absolute domination’ of high-end compute, it says, with world’s hugest chip two-dot-oh

Cerebras Systems product manager for AI Natalia Vassilieva holds the company’s WSE-2, a single chip measuring almost the entire surface of a twelve-inch semiconduor wafer. The chip was first unveiled in April, and is the heart of the new CS-2 machine, the company’s second version of its dedicated AI computer.
Cerebras Systems
The new elements this week are a rack-mounted box called MemoryX, which contains 2.4 petabytes combined of DRAM and NAND flash memory, to store all the weights of the neural net. A third box is a so-called fabric machine that connects the CS-2 to the MemoryX, called SwarmX. The fabric can connect as many as 192 CS-2 machines to the MemoryX to build a cluster that works cooperatively on a single large neural net.
Parallel processing on large problems typically comes in two kinds, data parallel or model parallel.
To date, Cerebras has exploited model parallelism, whereby the neural network layers are distributed across different parts of the massive chip, so that layers, and their weights, run in parallel. The Cerebras software automatically decides how to apportion layers to areas of the chip, and some layers can get more chip area than others.
Neural weights, or parameters, are matrices, typically represented by four bytes per weight, so the weight storage is basically a multiple of four times whatever the total number of weights are. For GPT-3, which has 175 billion parameters, the total area of the entire neural network would be 700 gigabytes.
A single CS-1 can hold all the parameters of a small or medium-sized network or all of a given layer of a large model such as GPT-3, without having to page out to external memory because of the large on-chip SRAM of 18 gigabytes.
“The largest layer in GPT-3 is about 12,000 x 48,000 elements,” said Feldman, speaking of the dimensions of a single weight matrix. “That easily fits on a single WSE-2.”
In the new WSE2 chip, which bumps up SRAM memory to 40 gigabytes, a single CS-2 machine can hold all the parameters that would be used for a given layer of a 120-trillion parameter neural net, says Cerebras. “At hot chips we are showing matrix multiplies of 48,000 x 48,000, twice as big as GPT-3,” he notes.
When used in combination with the MemoryX, in the streaming approach, the single CS-2 can process all the model weights as they are streamed to the machine one layer at a time.
The company likes to call that “brain-scale computing” by analogy to the 100 trillion synapses in the human brain.
The 120-trillion-parameter neural net in this case is a synthetic neural net developed internally by Cerebras for testing purposes, not a published neural net.
Although the CS-2 can hold all those layer parameters in one machine, Cerebras is now offering to use MemoryX to achieve data parallelism. Data parallelism is the opposite of model parallelism, in the sense that every machine has the same set of weights but a different slice of the data to work on.
To achieve data parallelism, Cerebras keeps all of the weights in MemoryX and then selectively broadcasts those weights to the CS-2s, where only the individual slice of data is stored.
Each CS-2, when it receives the streaming weights, applies those weights to the input data, and then passes the result through the activation function, a kind of filter that is also stored on chip, which checks the weighted input to see if a threshold is reached.
The end result of all that is the gradient, a small adjustment to the weights, which is then sent back to the MemoryX box where it is used to update the master list of weights. The SwarmX does all the back and forth routing between MemoryX and CS-2, but it also does something more.
“The SwarmX does both communication and calculation,” explained Feldman. “The SwarmX fabric combines the gradients, called a reduction, which means it does an operation like an average.”
And the result, says Feldman, is vastly higher utilization of the CS-2 compared to the competition even on today’s production neural nets such as GPT-3.
“Other people’s utilization is in the 10% or 20%, but we are seeing utilization between 70% and 80% on the largest networks — that’s unheard of,” said Feldman. The addition of systems offers what he called “linear performance scaling,” meaning that, if sixteen systems are added, the speed to train a neural net gets sixteen times faster.
As a result, “Today Each CS2 replaces hundreds of GPUs, and we now can replace thousands of GPUs” with the clustered approach, he said.
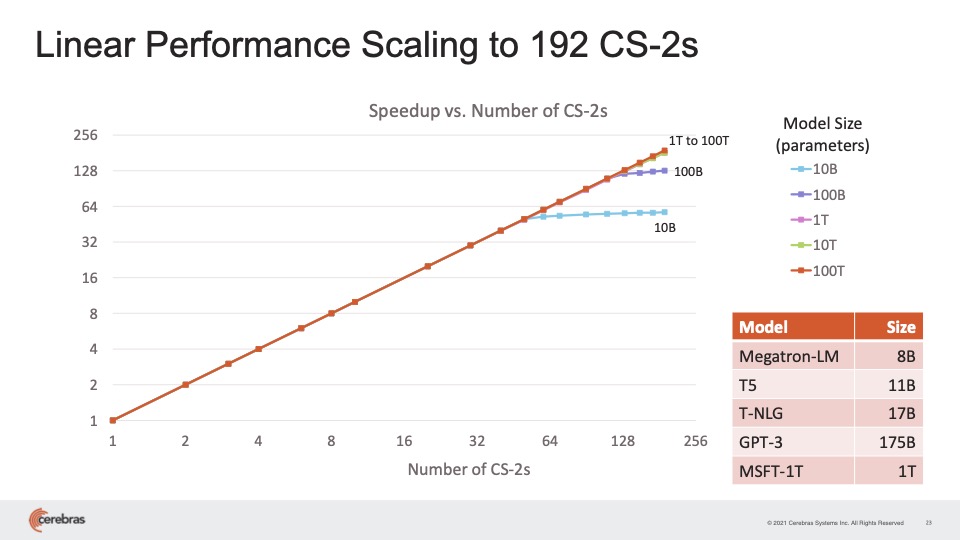
Cerebras claims the clustered machines produce linear scaling, meaning, for every number of machines added, the speed to train a network increases by a corresponding multiple.
Cerebras Systems
Parallelism is leads to an additional benefit, says Cerebras, and that is what’s called sparsity.

From the beginning, Cerebras has argued Nvidia GPUs are grossly inefficient because of their lack of memory. The GPU has to go out to main memory, DRAM, which is costly, so it fetches data in collections called batches. But that means that the GPU may operate on data that are zero-valued, which is a waste. And it also means that the weights aren’t updated as frequently while they wait for each batch to be processed.
The WSE, because it has that enormous amount of on-chip SRAM, is able to pull individual data samples, a batch of one, as it’s called, and operate on many such individual samples in parallel across the chip. And with each individual sample, it’s possible, again, with fast memory, to work on only certain weights and to update them selectively and frequently.
The company argues — in formal research and in a blog post by product manager for AI Natalia Vassilieva — that sparsity brings all kinds of benefits. It makes for more-efficient memory usage, and allows for dynamic parallelization, and it means that backpropagation, a backward pass through the neural weights, can be compressed into an efficient pipeline that further parallelizes things and speeds up training. That is an idea that seems to hold increasing interest in the field generally.
When it came time to move to a clustered system, Cerebras came up with a sparse approach again. Only some weights need be streamed to each CS-2 from the MemoryX, and only some gradients need be sent back to the MemoryX.
In other words, Cerebras claims its system-area network composed of computer, switch and memory store, behave like a large version of the sparse compute that happens on a single WSE chip.
Combined with the streaming approach, the sparsity in the CS-2, along with MemoryX and SwarmX, has a flexible, dynamic component that the company argues cannot be equaled by other machines.
“Each layer can have a different sparse mask,” said Feldman, “that we can give different sparsity per epoch, and over the training run we can change the sparsity, including sparsity that can take advantage of what’s learned during the training, called dynamic sparsity — no one else can do that.
Adding sparsity to data-parallelism, says Feldman, brings an order of magnitude speed-up in the time to train large networks.
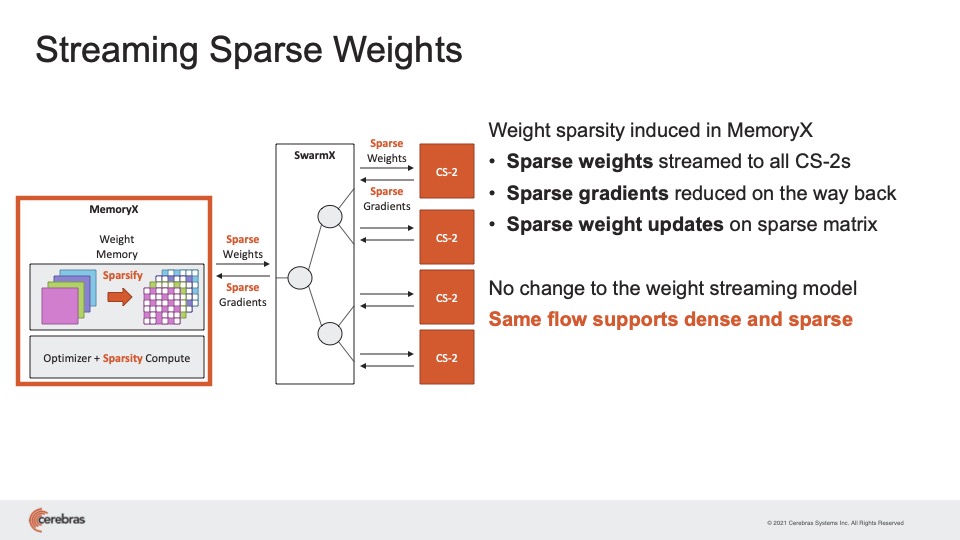
Cerebras advocates heavy and flexible use of the technique known as sparsity to bring added performance benefits.
Cerebras Systems
Of course, the art of selling many more CS-2 machines, along with the new devices, will depend on whether the market is ready for multi-trillion, or multi-tens-of-trillion-weight neural networks. The CS-2 and the other components are expected to ship in Q4 of this year, so, a couple of months from now.
Existing customers seem interested. Argonne National Laboratories, one of nine giant supercomputing centers of the U.S. Department of Energy, has been a user of the CS-1 system since the beginning. Although the lab isn’t yet working with the CS-2 nor the other components, the researchers are enthusiastic.
“The last several years have shown us that, for NLP [natural language processing] models, insights scale directly with parameters – the more parameters, the better the results,” said Rick Stevens, who is the associate director of Argonne, in a prepared statement.
Also: ‘We are doing in a few months what would normally take a drug development process years to do’: DoE’s Argonne Labs battles COVID-19 with AI
“Cerebras’ inventions, which will provide a 100x increase in parameter capacity, may have the potential to transform the industry,” said Stevens. “For the first time we will be able to explore brain-sized models, opening up vast new avenues of research and insight.”
Asked if the time is right for such horsepower, Feldman observed, “Nobody is putting matzah on the shelves in January,” referring to the traditional unleavened bread that is only stocked exactly when needed, just before the Passover holiday in the springtime.
The time for massive clusters of AI machines has come, Feldman said.
“This is not matzah in January,” he said.

