
The world is about to be deluged by artificial intelligence software that could be inside of a sticker stuck to a lamppost.
What’s called TinyML, a broad movement to write machine learning forms of AI that can run on very-low-powered devices, is now getting its own suite of benchmark tests of performance and power consumption.
The test, MLPerf, is the creation of the MLCommons, an industry consortium that already issues annual benchmark evaluations of computers for the two parts of machine learning, so-called training, where a neural network is built by having its settings refined in multiple experiments; and so-called inference, where the finished neural network makes predictions as it receives new data.
Those benchmark tests, however, were focused on conventional computing devices ranging from laptops to supercomputers. MLPerf Tiny Inference, as the new exam is called, focuses on the new frontier of things running on smartphones down to things that could be thin as a postage stamp, with no battery at all.
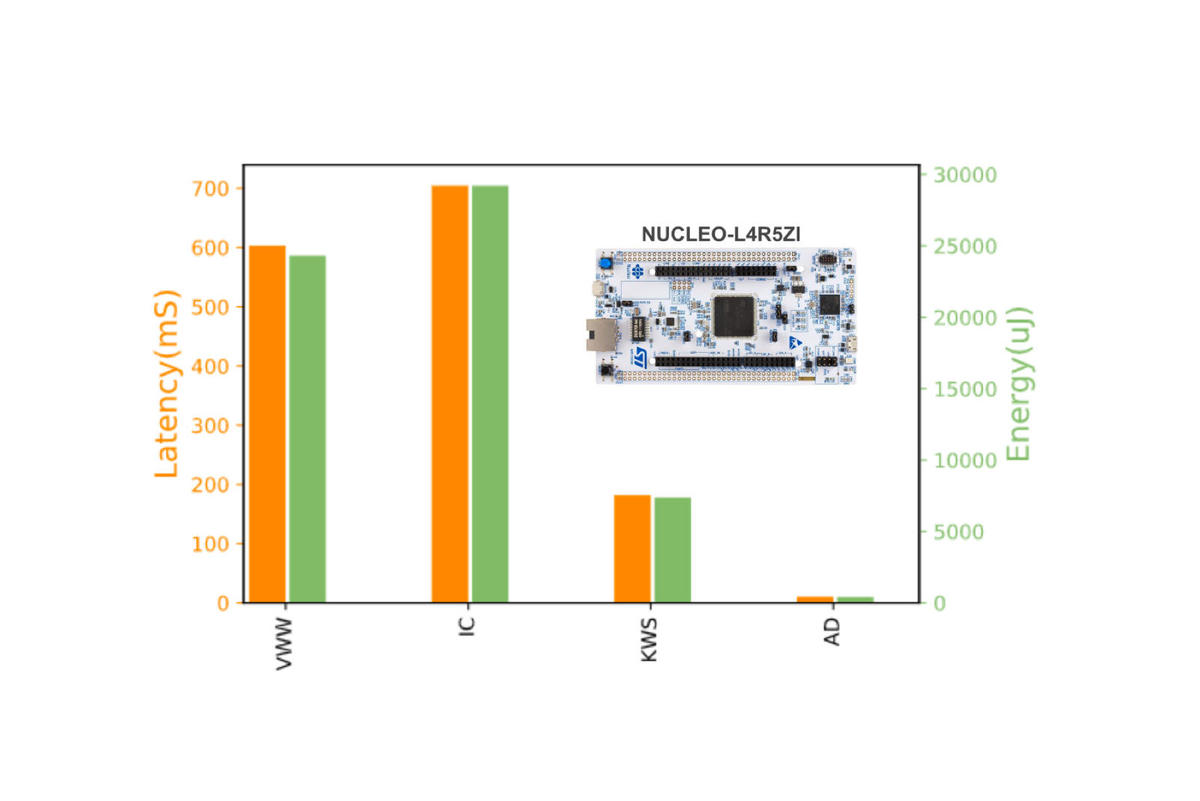
The reference implementation for MLPerf Tiny Inference tests how much latency is incurred and how much energy is consumed running four representative machine learning takss on an ST MIcroelectronics Nucleo ARM-based microcontroller board for embedded systems.
“This completes the micro-watts to megawatts benchmarks spectrum,” said David Kanter, the executive director of MLCommons, the industry consortium that oversees MLPerf, in a briefing with press.
Also: AI industry’s performance benchmark, MLPerf, for the first time also measures the energy that machine learning consumes
The tests measure latency in milliseconds and power consumption in micro-Jules, to complete four representative machine learning tasks, where lower is better in both cases. This is the second time that ML Commons has introduced an energy measurement. In April, the group introduced a measure of AC power used, in watts, into the existing MLPerf Inference test.
TinyML represents fairly tasks that are familiar to many using mobile devices, things such as the wake word that activates a phone, such as “Hey, Google,” or “Hey, Siri.” (Warden confided to the audience, with a chuckle, that he and colleagues have to refer to “Hey, Google” around the office as “Hey, G,” in order not to have one another’s phones going off constantly.)
In this case, the four tasks included keyword spotting, but also three others: what’s called visual wake words, where an object in a field of view triggers some activity (think video doorbell); image classification on the widely used CIFAR-10 data set; and anomaly detection, a visual inspection system that might be used in a factory floor.

The benchmark was constructed by making a reference implementation, where those four tasks are run on a small embedded computer board, the ST Microelectronics’ Nucleo-L4R5ZI, which runs an ARM Cortex-M4 embedded processor.
The Nucleo is deemed by ML Commons to be in sufficiently wide use to represent very low power devices. The Nucleo ran Google’s software system for TinyML, called TensorFlow Lite, in this case a version specially designed for microcontrollers.
Four groups submitted their results to the benchmark: Syntiant, an Irvine, California-based designer of AI processors; LatentAI, a Menlo Park, California-based spin-out of research institute SRI International that makes a developer SDK for AI; Peng Cheng Laboratory, a research laboratory in Shenzen, China; and hls4ml, a collection of researchers from Fermilab, Columbia University, UC San Diego, and CERN.
Syntiant ran the benchmark on an ARM Cortex-M0 processor, while LatentAI used a Raspberry Pi 4 system with a Broardcom chip, and hls4ml used a Xilinx processor on a Pynq-Z2 development board.
Perhaps the most interesting submission from a hardware standpoint was Peng Cheng Laboratory’s custom processor, which it designed, and which was fabricated by China’s Semiconductor Manufacturing International. That part runs the open RISC-V instruction set, a project of the University of California at Berkeley that has been gaining increasing support as an alternative to ARM chip instructions.
A formal paper describing the benchmark is available for download on OpenReview.net, authored by two of the academic advisors to the organization, Colby Banbury and Vijay Janapa Reddi of Harvard University, along with multiple contributing authors. That paper has been submitted to this year’s NeurIPS, the AI field’s biggest academic conference.
The benchmark was created over the course of eighteen months via collective input from ML Commons working members that include representatives from CERN, Columbia University and UC San Diego, Google, chip makers Infineon, Qualcomm, Silicon Labs, STMicro, and Renesas, AI startup SambaNova Systems, and chip design software maker Synopsys, among others.
Reddi of Harvard said the design was a result of both voting by those advisors but also a process of selecting from among the suggestions.
“It is driven by vote, but we do want to understand what the feedback is from consumers or customers,” said Reddi.
“There is an element of group consensus, and there is an element of feasibility,” said Kanter, meaning, dealing with the limitations of what data sets can in practice be used for tests. “If you aren’t evaluating on a real data set, you are not going to get super-meaningful results,” he said. Datasets such as CIFAR-10 ensure results will be “comparable and well recognized,” he added.
“That’s a gating factor,” said Kanter of the dataset issue. “There are a lot applications that we would love to be able to measure performance on, but, ultimately, you sort-of look at what are the availabe resources, especially given this is an initial effort.”
One of the biggest challenges of benchmarking TinyML is that the software stack, all the coding layers from hardware instruction sets on up through the frameworks of machine learning, such as Google’s TensorFlow Lite, constitute a much more varied collection of software than is usually found in programs written for PCs and supercomputers in TensorFlow, PyTorch, and Nvidia’s CUDA software engine.
The tests allow companies that submit to both use their own version of a neural network algorithm, or to use a standard model, the same as everyone else, dubbed either “open” or “closed” benchmark results, respectively.
An additional complication is defining the exact power envelope. “Measuring power for battery-based systems is very challenging,” noted Kanter. The embedded board systems used in the test suite run in a controlled test set-up where their absolute runtime power for the tasks is “intercepted” by a power monitor that is, in fact, supplying the power.
“We just cut out the entire battery subsystem,” said Peter Torelli, president of the Embedded Microprocessor Benchmark Consortium, a group that has for decades measured performance of embedded systems, which worked on the energy component of the benchmark.
Also: Machine learning at the edge: TinyML is getting big
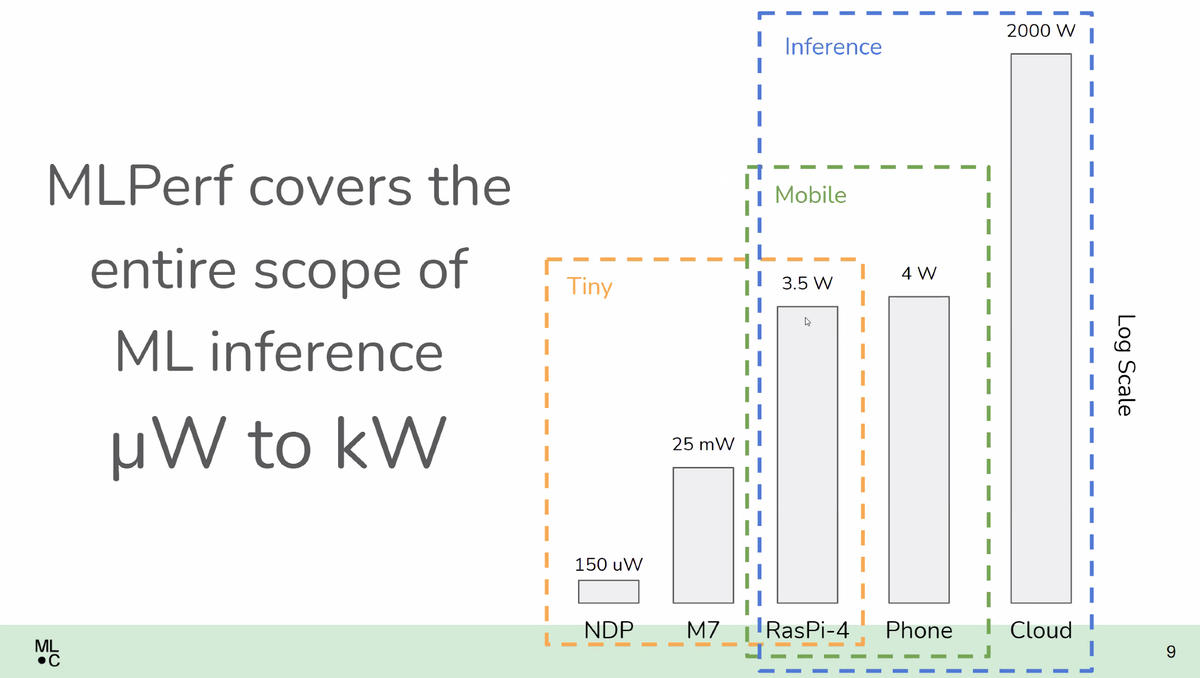
In the real world, a diverse set of circumstances will greet any device that actually runs in a mobile phone or a factory floor device. Google’s head of development for TinyML, Pete Warden, has argued that TinyML efforts should focus on devices that are battery powered, with no wall-socket connection.
Warden has suggested that even simpler TinyML devices could be using energy harvesting, so that they don’t even have a battery, but rather would be provided their energy via the sun or via heat-emitting organisms or structures nearby.
Although in principle the ML Commons is in accord with Warden’s view that many TinyML devices will have battery power only, or energy harvesting, the benchmarks include devices such as the Raspberri Pi that could be using a wall power source. At 3.5 watts of power, the Raspberri Pi is quite a bit larger than the micro-watts of the smallest kinds of embedded systems.
Also: Google AI executive sees a world of trillions of devices untethered from human care

