Arguably one of the premiere events that has brought AI to popular attention in recent years was the invention of the Transformer by Ashish Vaswani and colleagues at Google in 2017. The Transformer led to lots of language programs such as Google’s BERT and OpenAI’s GPT-3 that have been able to produce surprisingly human-seeming sentences, giving the impression machines can write like a person.
Now, scientists at DeepMind in the U.K., which is owned by Google, want to take the benefits of the Transformer beyond text, to let it revolutionize other material including images, sounds and video, and spatial data of the kind a car records with LiDAR.
The Perceiver, unveiled this week by DeepMind in a paper posted on arXiv, adapts the Transformer with some tweaks to let it consume all those types of input, and to perform on the various tasks, such as image recognition, for which separate kinds of neural networks are usually developed.
The DeepMind work appears to be a waystation on the way to an envisioned super-model of deep learning, a neural network that could perform a plethora of tasks, and would learn faster and with less data, what Google’s head of AI, Jeff Dean, has described as a “grand challenge” for the discipline.
One model to rule them all? DeepMind’s Perceiver has decent performance on multiple tests of proficiency even though the program is not built for any one kind of input, unlike most neural networks that specialize. Perceiver combines a now-standard Transformer neural network with a trick called “inducing points,” as a summary of the data, to reduce how much raw data from pixels or audio or video needs to be computed.
DeepMind
The paper, Perceiver: General Perception with Iterative Attention, by authors Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira, is to be presented this month at the International Conference on Machine Learning, which kicks of July 18th and which is being held as a virtual event this year.
Perceiver continues the trend to generality that has been underway for several years now, meaning, having less and less built into an AI program that is specific to a task. Before Vaswani et al.’s Transformer, most natural language programs were constructed with a sense of the particular language function, such as question answering or language translation. Transformer erased those distinctions, producing one program that could handle a multitude of tasks by creating a sufficiently adept representation of language.
Also: AI in sixty seconds
Likewise, Perceiver challenges the idea that different kinds of data, such as sound or image, need different neural network architectures.
However, something more profound is indicated by Perceiver. Last year, at the International Solid State Circuits Conference, an annual technical symposium held in San Francisco, Google’s Dean described in his keynote address one future direction of deep learning as the “goal of being able to train a model that can perform thousands or millions of tasks in a single model.”
“Building a single machine learning system that can handle millions of tasks … is a true grand challenge in the field of artificial intelligence and computer systems engineering,” said Dean.
In a conversation with ZDNet at the conference, Dean explained how a kind of super-model would build up from work over the years on neural networks that combine “modalities,” different sorts of input such as text and image, and combinations of models known as “mixture of experts”:
Mixture of experts-style approaches, I think, are going to be important, and multi-task, and multi-modal approaches, where you sort-of learn representations that are useful for many different things, and sort-of jointly learn good representations that help you be able to solve new tasks more quickly, and with less data, fewer examples of your task, because you are already leveraging all the things you already know about the world.
Perceiver is in the spirit of that multi-tasking approach. It takes in three kinds of inputs: images, videos, and what are called point clouds, a collection of dots that describes what a LiDAR sensor on top of a car “sees” of the road.
Once the system is trained, it can perform with some meaningful results on benchmark tests, including the classic ImageNet test of image recognition; Audio Set, a test developed at Google that requires a neural net to pick out kinds of audio clips from a video; and ModelNet, a test developed in 2015 at Princeton whereby a neural net must use 2,000 points in space to correctly identify an object.
Also: Google experiments with AI to design its in-house computer chips
Perceiver manages to achieve the task using two tricks, or, maybe, one trick and one cheat.
The first trick is to reduce the amount of data that the Transformer needs to operate on directly. While large Transformer neural networks have been fed gigabytes and gigabytes of text data, the amount of data in images or video or audio files, or point clouds, is potentially vastly larger. Just think of every pixel in a 244 by 244 pixel image from ImageNet. In the case of a sound file, “1 second of audio at standard sampling rates corresponds to around 50,000 raw audio samples,” write Jaegle and team.
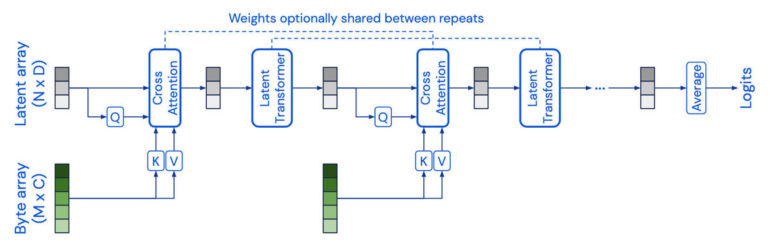
So, Jaegle and team went in search of a way to reduce the so-called “dimensionality” of those data types. They borrow from the work of Juho Lee and colleagues at Oxford University, who introduced what they called the Set Transformer. The Set Transformer reduced the computing needed for a Transformer by creating a second version of each data sample, a kind of summary, which they called inducing points. Think of it as data compression.
Jaegle and team adapt this as what they call a “learned latent array,” whereby the sample data is boiled down to a summary that is far less data-hungry. The Perceiver acts in an “asymmetric” fashion: Some of its abilities are spent examining the actual data, but some only look at the summary, the compressed version. This reduces the overall time spent.
The second trick, really kind of a cheat, is to give the model some clues about the structure of the data. The problem with a Transformer is that it knows nothing about the spatial elements of an image, or the time value of an audio clip. A Transformer is always what’s called permutation invariant, meaning, insensitive to these details of the structure of the particular kind of data.
That is a potential problem baked into the generality of the Perceiver. Neural networks built for images, for example, have some sense of the structure of a 2-D image. A classic convolutional neural network processes pixels as groups in a section of the image, known as locality. Transformers, and derivatives such as Perceiver, aren’t built that way.
The authors, surprisingly, cite the 18th-century German philosopher Immanuel Kant, who said that such structural understanding is crucial.
“Spatial relationships are essential for sensory reasoning,” Jaegle and team write, citing Kant, “and this limitation is clearly unsatisfying.”
So, the authors, in order to give some sense of the structure of images or sound back to the neural network, borrow a technique employed by Google’s Matthew Tancik and colleagues last year, what are called Fourier features. Fourier Features explicitly tag each piece of input with some meaningful information about structure.
For example, the coordinates of a pixel in an image can be “mapped” to an array, so that locality of data is preserved. The Perceiver then takes into account that tag, that structural information, during its training phase.
As Jaegle and team describe it,
We can compensate for the lack of explicit structures in our architecture by associating position and modality-specific features with every input element (e.g. every pixel, or each audio sample) – these can be learned or constructed using high-fidelity Fourier features. This is a way of tagging input units with a high-fidelity representation of position and modal- ity, similar to the labeled lined strategy used to construct topographic and cross-sensory maps in biological neural networks by associating the activity of a specific unit with a semantic or spatial location.
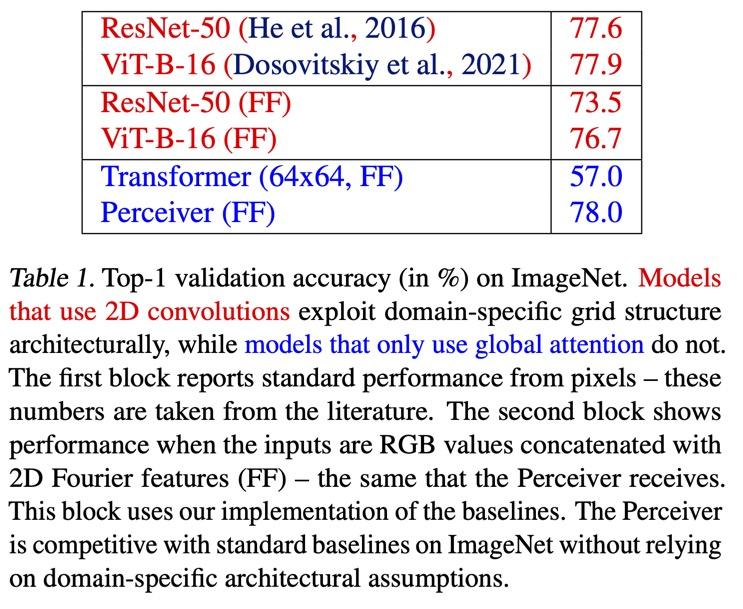
The results of the benchmark tests are intriguing. Perceiver is better than the industry standard ResNet-50 neural network on ImageNet, in terms of accuracy, and better than a Transformer that has been adapted to images, the Vision Transformer introduced this year by Alexey Dosovitskiy and colleagues at Google.
On the Audio Set test, the Perceiver blows away most but not all state-of-the-art models for accuracy. And on the ModelNet test of point clouds, the Perceiver also gets quite high marks.
Jaegle and team claim for their program a kind of uber-proficiency that wins by being best all around: “When comparing these models across all different modalities and combinations considered in the paper, the Perceiver does best overall.”
There are a number of outstanding issues with Perceiver that make it perhaps not actually the ideal million-task super-model that Dean has described. One is that the program doesn’t always do as well as programs made for a particular modality. It still fails against some specific models. For example, on Audio Set, the Perceiver fell short of a program introduced last year by Haytham M. Fayek and Anurag Kumar of Facebook that “fuses” information about audio and video.

On the point cloud, it falls far short of a 2017 neural network built just for point clouds, PointNet++, by Charles Qi and colleagues at Stanford.
And on ImageNet, clearly the Perceiver was helped by the cheat of having Fourier features that tag the structure of images. When the authors tried a version of the Perceiver with the Fourier features removed, called “learned position,” the Perceiver didn’t do nearly as well as ResNet-50 and ViT.
A second issue is that nothing about Perceiver appears to bring the benefits of more-efficient computing and less data that Dean alluded to. In fact, the authors note that the data they use isn’t always big enough. They observe that sometimes, the Perceiver may not be successfully generalizing, quipping that “With great flexibility comes great overfitting.” Overfitting is when a neural network is so much bigger than its training data set, that it is able to simply memorize the data rather than achieve important representations that generalize the data.
Hence, “In future work, we would like to pre-train our image classification model on very large scale data,” they write.
That leads to a larger question about just what is going on in what the Perceiver has “learned.” If Google’s Jeff Dean is right, then something like Perceiver should be learning representations that are mutually reinforcing. Clearly, the fact of a general model being able to perform well in spite of its generality suggests that something of the kind is going on. But what?
All we know is that Perceiver can learn different kinds of representations. The authors show a number of what are called attention maps, visual studies that purport to represent what the Perceiver is emphasizing in each clump of training data. Those attention maps suggest the Perceiver is adapting where it places the focus of computing.
As Jaegle and team write, “it can adapt its attention to the input content.”

An attention map purports to show what the Perceiver is emphasizing in its video inputs, showing it is learning new represenations specific to the “modality” of the data.
DeepMind
A third weakness is specifically highlighted by the authors, and that is the question of the Fourier features, the cheat. The cheat seems to help in some cases, and it’s not clear how or even if that crutch can be dispensed with.
As the authors put it, “End-to-end modality-agnostic learning remains an interesting research direction.”
On a philosophical note, it’s interesting to wonder if Perceiver will lead to new kinds of abilities that are specifically multi-modal. Perceiver doesn’t show any apparent synergy between the different modalities, so that image and sound and point clouds still exist apart from one another. That’s probably mostly to do with the tasks. All the tasks used in the evaluation have been designed for single neural networks.
Clearly, Google needs a new benchmark to test multi-modality.
For all those limitations, it’s important to realize that Perceiver may be merely a stage on the way to what Dean described. As Dean told ZDNet, an eventual super-model is a kind of evolutionary process:
The nice thing about that vision of being able to have a model that does a million tasks is there are good intermediate points along the way. You can say, well, we’re not going to bite off multi-modal, instead let’s try to just do a hundred vision tasks in the same model first. And then a different instance of it where we try to do a hundred textual tasks, and not try to mix them together. And then say, that seems to be working well, let’s try to combine the hundred vision and hundred textual tasks, and, hopefully, get them to improve each other, and start to experiment with the multi-modal aspects.
Also: Ethics of AI: Benefits and risks of artificial intelligence

