
For the past few years, I’ve been wondering how the Intel era was going to end. At Apple’s Unleashed event on Monday, we got a glimpse of how that could play out.
I’m not here to tell you that the future of personal computing is Apple Silicon Macs. But what you are going to see develop over the next several years is a systems architecture that looks very Mac-like, regardless of which operating system you end up running. And it won’t matter if it’s on chips of Apple’s own design, or chips designed by Qualcomm, NVIDIA, Samsung, Microsoft, or even Google.
Get on the bus
The predominant systems architecture of the past 40 years has been x86. It’s not just that instruction set, however, that has been dominant. It’s also all of the other components in PCs and x86 servers that have been predominant, such as the various bus architectures and support chips.
PCs, big iron servers, and really all computers since the 1960s have been designed using what are referred to as bus architectures. A bus is roughly analogous to the human body’s nervous system; it’s used to move data between parts of a computer system, which includes the CPU, system cache, GPU, and specialized processor units for Machine Learning and other functions. It also moves data to and from main memory (RAM), video memory attached to the GPU, and all I/O components — keyboard, mouse, Ethernet, WiFi, and/or Bluetooth.
Without the bus, data does not move.
The rise of SoCs
The computer industry has developed different bus architectures, such as the different iterations of PCI for the I/O components and various other types developed for video graphics. They are the fundamental building blocks of designing a microcomputer, regardless of what company makes it. We have desktop and server versions of these, and we also have mobile/laptop versions.
As we moved into the mobile computing and embedded computing space, however, we had to put more and more of these system components onto the chip itself, so now we call them Systems on a Chip or SoCs. The CPUs, GPUs, ML cores, main memory, video memory, and even the primary storage can now all live on a single chip.
There are some key advantages to doing it this way — mainly the reduction of bottlenecks. When you need to use a bus to transfer data from one system component to the next, you must change interface technologies. In many cases, you may have fewer data lanes to move that information, which is like going on an off-ramp from the expressway with eight lanes of traffic to two before you can get onto another expressway going in a different direction. When this is done on the chip itself, that bottleneck doesn’t (have to) exist.
ZDNet Recommends

Best Mac 2021
Apple’s Mac lineup can be confusing as the company transitions from Intel processors to its own Apple Silicon processors. But we’re here to help.
Read More
But there have been limitations to what you can do with SoCs. There are only so many CPU and GPU cores you can put on them, and there is only so much memory you can stack on a die. So while SoCs work very well for smaller computer systems, they aren’t used for the most powerful PC and server workloads; they don’t scale to the biggest systems of all. To have scale on a desktop, to make a workstation with hundreds of gigabytes or terabytes of RAM that you see in the film or aerospace industries, you need to be able to do this. It’s the same deal in a data center or a hyperscale cloud for large-scale enterprise workloads. The less copying memory across dense, slower bus interfaces, the better.
Enter M1 and UMA
With the new Apple M1 Pro and M1 Max SoCs, many more transistors are on the die, which typically translates into more speed. But what is really exciting about these new chips is the memory bus bandwidth.
Over the last year, I’ve been wondering how Apple was going to scale this architecture. Specifically, how they were going to handle the issue of increasing bus speeds between main memory (RAM) and the GPU. On desktop computers using Intel architecture, this is done in a non-uniform fashion, or NUMA.
Intel systems typically use discrete memory, such as DDR, on a GPU, and then they use a high-speed memory bus interconnect between it and the CPU. The CPU is connected via another interconnect to main memory. But the M-series and the A-series use Unified Memory Architecture; in other words, they pool a base of RAM together between the CPU, GPU, and Machine Learning cores (Neural Engine). Effectively, they share everything.

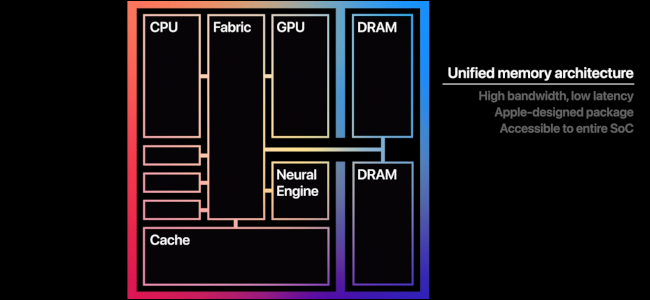
Unified Memory Architecture on the M1 SoC
Apple
And they share it very fast. In the M1 Pro, that is 200 Gigabytes per Second (GB/s), and in the M1 Max, that is 400GB/s. So those super-fast GPU cores — of which there are up to 32 on the Max — have super-fast communication bandwidth to those super-fast CPU cores — of which there are up to 10 on both the M1 Pro and M1 Max. And we aren’t even talking about those specialized Machine Learning cores that also take advantage of this bus speed.
Of course, the M1 Pro and M1 Max can take a lot more memory than last year’s models as well — up to 64GB of RAM. Certainly, the M1 was not slow on a per-core basis compared to the rest of the industry. But if Apple wants to get the highest-end professional workloads running, they needed to do this to make that bus bandwidth fly.
Scaling Arm from M1 Mac to Datacenters and Big Iron
Now here is where things get interesting.
I really want to see what they will do with the Mac Mini and the Mac Pro. I expect the updated Mini to use the same mainboard design as these new Macbook Pro systems. But the Pro is likely to be a monster system, potentially allowing more than one M1 Max on it. That means they will have needed to develop a way to pool memory across SoCs — something we have not seen occur in the industry yet because of bus latency issues.
One possibility will be to make the Pro into a desktop cluster of multiple Mini daughterboards tied into some kind of super-fast network. The industry looked at desktop clusters for scientific workloads some 10-15 years ago using Arm chips, Linux, and open-source cluster management software used in supercomputers (Beowulf). Still, they did not take off; it was not practical to redesign those types of desktop apps to work in a parallelized function over a TCP/IP network.
It may finally be viable with the bus connection technology used in Apple’s M1 SoCs. Because if you can connect a CPU die and a GPU die on a single mainboard — and share that memory at very high speeds — you should be able to connect additional CPU and GPU matrices across multiple mainboards or daughterboards. So, perhaps, the desktop cluster is the future of the Mac Pro.
All of this is exciting, and yes, we will see the Mac implement all of these technologies first. But other big tech companies are developing more powerful Arm-based SoCs, too. So while you may not be using a Mac in the next several years for business and other workloads, your PC might very well look like one on the inside.

