The large language models that have increasingly taken over the tech world are not “cheap” in many ways. The most prominent LLMs, such as GPT-4, took some $100 million to build in the form of legal costs of accessing training data, computational power costs for what could be billions or trillions of parameters, the energy and water needed to fuel computation, and the many coders developing the training algorithms that must run cycle after cycle so the machine will “learn.”
But, if a researcher needs to do a specialized task that a machine could do more efficiently and they don’t have access to a large institution that offers access to generative AI tools, what other options are available? Say, a parent wants to prep their child for a difficult test and needs to show many examples of how to solve complicated math problems.
Building their own LLM is an onerous prospect for costs mentioned above, and making direct use of the big models like GPT-4 and Llama 3.1 might not immediately be suited for the complex reasoning in logic and math their task requires.
It would help if there were a more cost-effective version of a large language model thinker available to the masses, a generic brand for generative AI.
Researchers at Washington University in St. Louis decided to tackle this challenge by building an autonomous agent to instruct the reasoning process of large language models. This agent generates a single set of instructions for each task and those instructions turn out to be extremely effective for improving the reasoning process of different LLMs across all task instances, according to research from the lab of Chenguang Wang, assistant professor in computer science and engineering, in collaboration with Dawn Song, a professor at the University California, Berkeley.
Researchers included WashU Ph.D. students Nicholas Crispino, Kyle Montgomery, and research analyst Fankun Zeng, who presented their work at a recent conference for machine learning. The work is also available on the arXiv preprint server.
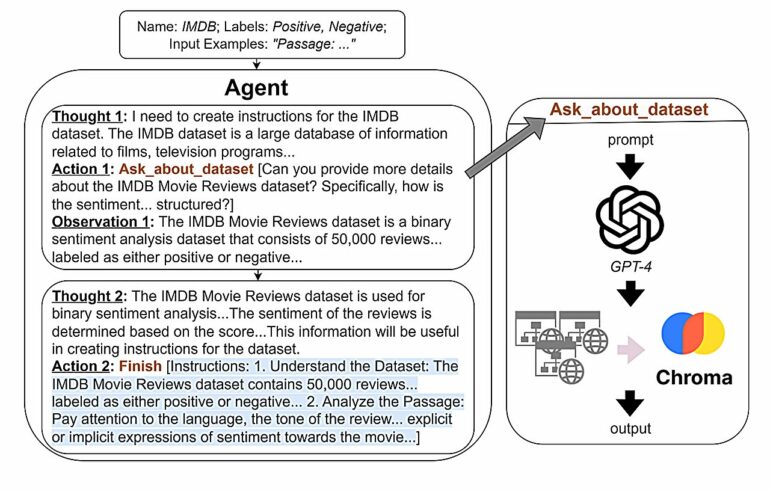
This “agent” is a large LLM that serves as a tool to think over the instructions from the web, said Crispino. Given basic task information such as the dataset name, and a few input-only examples, the agent then produces high quality step-by-step instructions for tasks.
Those instructions guide the reasoning of the smaller LLMs on certain tasks. It’s a more affordable way to do generative AI because they only have to use the large LLM once per data set, then they hand instructions over to a smaller LLM that can take over.
“We can use the expensive model once and make these nice instructions to guide the reasoning or thinking process of a cheaper model,” Crispino said.
“Our method boosts the performance of state-of-the-art large language models by a large margin,” Montgomery added.
They tested their cost-effective method, called Zero-Shot AgentInstruct, on language processing tasks and compared its performance to zero-shot prompting methods using LLMs Vicuna-13b, Llama-2-70b-chat, and GPT-3.5 Turbo.
Compared to the “zero-shot chain of thought” prompting, which works via adding the prompt “Let’s think step by step,” Zero-Shot AgentInstruct showed better performance across a variety of tasks evaluated on 29 datasets (including 53 subsets).
“Our improvement in thinking and reasoning is striking, particularly in math and logic,” Wang said.
Essentially, they are making use of the powerful LLM models to distill tasks into step-by-step reasoning paths for the other model, like an experienced teacher sharing their knowledge with students.
“We’re seeing how far we can push the reasoning capabilities of smaller models using larger models without training,” Crispino said.
More information:
Nicholas Crispino et al, Agent Instructs Large Language Models to be General Zero-Shot Reasoners, arXiv (2023). DOI: 10.48550/arxiv.2310.03710
Provided by
Washington University in St. Louis
Citation:
Language agents help large language models ‘think’ better and cheaper (2024, September 24)

