The field of machine learning is traditionally divided into two main categories: “supervised” and “unsupervised” learning. In supervised learning, algorithms are trained on labeled data, where each input is paired with its corresponding output, providing the algorithm with clear guidance. In contrast, unsupervised learning relies solely on input data, requiring the algorithm to uncover patterns or structures without any labeled outputs.
In recent years, a new paradigm known as “self-supervised learning” (SSL) has emerged, blurring the lines between these traditional categories. Supervised learning depends heavily on human experts to label data and serve as the “supervisor.” However, SSL bypasses this dependency by using algorithms to generate labels automatically from raw data.
SSL algorithms are used for a wide range of applications, from natural language processing (NLP) to computer vision, bioinformatics, and speech recognition. Traditional SSL approaches encourage the representations of semantically similar (positive) pairs to be close, and those of dissimilar (negative) pairs to be more apart.
Positive pairs are typically generated using standard data augmentation techniques like randomizing color, texture, orientation, and cropping. The alignment of representations for positive pairs can be guided by either invariance, which promotes insensitivity to these augmentations, or equivariance, which maintains sensitivity to them.
The challenge, however, is that enforcing invariance or equivariance to a pre-defined set of augmentations introduces strong “inductive priors”—inherent assumptions about the properties that the learned representations are required to satisfy—which are far from universal across a range of downstream tasks.
In a paper posted to the arXiv preprint server, a team from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and the Technical University of Munich have proposed a new approach to self-supervised learning that addresses these limitations of relying on pre-defined data augmentations, and instead learns from a general representation that can adapt to different transformations by paying attention to context, which represents an abstract notion of a task or environment.
This allows learning data representations that are more flexible and adaptable to various downstream tasks, diverse symmetries, and sensitive features, eliminating the need for repetitive retraining for each task.
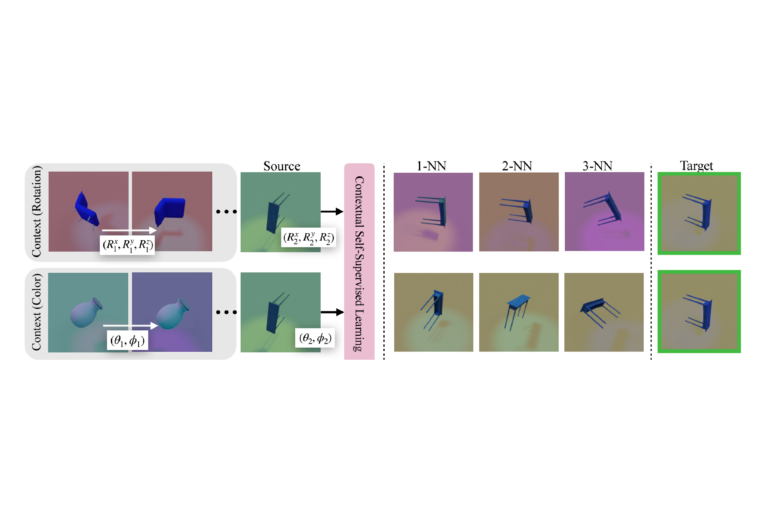
Calling their method “Contextual Self-Supervised Learning” (ContextSSL), the researchers demonstrate its effectiveness through extensive experiments on several benchmark datasets. The core idea is to introduce context inspired by world models—representations of an agent’s environment that capture its dynamics and structure.
By incorporating these world models, the approach enables the model to dynamically adapt its representations to be invariant or equivariant based on the task at hand. This eliminates the need for training separate representations for each downstream task and allows for a more general and flexible approach to SSL.
ContextSSL utilizes a transformer module to encode context as a sequence of state-action-next-state triplets, representing previous experiences with transformations. By attending to the context, the model learns to selectively enforce invariance or equivariance based on the transformation group represented in the context.
“Specifically, our goal is to train representations that become more equivariant to the underlying transformation group with increasing context,” says CSAIL Ph.D. student Sharut Gupta, lead author on the new paper from researchers that include MIT professors Tommi Jaakkola and Stefanie Jegelka. “We do not want to fine-tune models each time, but to build a flexible general-purpose model that could attend to different environments similar to how humans do.”
ContextSSL demonstrates significant performance gains on several computer vision benchmarks, including 3DIEBench and CIFAR-10, for tasks requiring both invariance and equivariance. Depending on the context, the representation learned by ContextSSL adapts to the right features that were useful for a given downstream task.
As an example, the team tested ContextSSL’s ability to learn representations for the particular attribute of gender on MIMIC-III, a large collection of medical records that includes crucial identifiers like medications, patient demographics, hospital length of stay (LOS), and survival data.
The team investigated this dataset since it captures real-world tasks benefiting from both equivariance and invariance: Equivariance is crucial for tasks like medical diagnosis where medication dosages depend on gender and physiological characteristics of patients, while invariance is essential for ensuring fairness in predicting outcomes like length of hospital stays or medical costs.
The researchers ultimately found that, when ContextSSL attends to gender-sensitivity-promoting context, both gender prediction accuracy and medical treatment prediction improve with context. On the contrary, when the context promotes invariance, performance improves on length of hospital stay (LOS) prediction and various fairness metrics measured by equalized odds (EO) and equality of opportunity (EOPP).

“A key goal of self-supervised learning is to generate flexible representations that can be adapted to many downstream tasks,” says Google DeepMind Senior Staff Research Scientist Dilip Krishnan, who wasn’t involved in the paper. “Rather than baking in invariance or equivariance a priori, it is much more useful to decide these properties in a task-specific manner.
“This interesting paper takes an important step in this direction. By cleverly leveraging the in-context learning abilities of transformer models, their approach can be used to impose invariance or equivariance to different transformations in a simple and effective manner.”
More information:
Sharut Gupta et al, In-Context Symmetries: Self-Supervised Learning through Contextual World Models, arXiv (2024). DOI: 10.48550/arxiv.2405.18193
Provided by
Massachusetts Institute of Technology
Citation:
Self-supervised machine learning adapts to new tasks without retraining (2024, December 23)

