
A panel talk Friday afternoon brought together AI scholars Gary Marcus, Yoshua Bengio, Daniel Kahneman, Luis Lamb, and moderator Francesca Rossi, for a spirited discussion of where machines and humans differ in their processing of abstract thought, logic, reason and many, many related questions.
NeurIPS 2020
The crown jewel of AI conferences each year is the NeurIPS conference, which is regularly over-subscribed, and which usually takes place in pretty cities such as Montreal, Vancouver, and Barcelona.
This year, the event was fully virtual because of the pandemic. While not as scenic, it was a well-organized, very rich six days of poster sessions, oral presentations, tutorials, workshops, symposia, invited talks, and some virtual wine and cheese thrown in, ending this past Friday, December 11th. They even managed to do some neat things with poster sessions. The whole conference as made possible via the open-source software Miniconf, along with use of Zoom and RocketChat.
Here’s a rundown of some of the highlights. This is by no means a comprehensive survey. For the full conference schedule, see the NeurIPS site here.
Industrial AI
Sunday, December 6th, kicked off with the Expo, a showcase of industrial uses of machine learning. The day included workshops running about four hours long with multiple presentations from researchers at Apple, Google, Netflix, IBM and Facebook, among others.
Interesting presentations included a whole workshop by Google on using graphs in various ways, including neural network operations over graphs. A session by Apple dove into details of how the recently unveiled M1 chip in the Mac is able to speed up training of models in TensorFlow. The company is even posting its tweaked TensorFlow code on GitHub for downloading.
Netflix included a wealth of material about personalization, of course, and hinted at future work pertaining to how to create content with ML.
For anyone who loves systems engineering and containers, there was a fascinating talk by Netflix’s Benoit Rostykus on how the company’s using ML to make the Netflix container platform smarter. The central problem is that on any machine, there is contention among containers for caches. And there is a high variance in terms of the latency in accessing memory, and optimizing that contention becomes a combinatorial problem.

Benoit Rostykus of Netflix talked about how the company is using machine learning to make the Netflix container platform smarter. He summed up all the combinatorial problems, saying, “I kind-of think of the data center as a giant Tetris,” trying to match jobs like the falling pieces in the game to the resources, the odd-shaped bed of forms at the bottom of the screen.
NeurIPS 2020
Rostykus said Netflix has been able to improve upon what the operating system of the machine does by modeling the tail of the distribution of cache access, to identify the worst performers. “Large neural networks are able to jointly predict the conditional distribution of the runtime duration of a batch job, or the predicted CPU usage distribution of this container in the next ten minutes or the next hour,” as he described it.
Summing up all the combinatorial problems, Rostykus said “I kind of think of the data center as a giant Tetris,” trying to match jobs like the falling pieces in the game to the resources, the odd-shaped bed of forms at the bottom of the screen.
IBM held a workshop on combining deep learning networks with symbolic AI, called “neuro-symbolic AI,” featuring work with partners Stanford and MIT. The idea, as explained by IBM researcher David Cox, is that maybe it’s about time that symbolic AI has a resurgence akin to that of deep learning. “We would argue symbolic AI has been waiting, perhaps for neural networks to start working.” Now that neural networks do work, he suggested, the path foreword might be to combine the two to complement each other.
As explained by his colleague, Alex Gray, a way to merge traditional logic-gate neurons with differentiable neurons is to use real-valued logic gates, and add weightings to them. Then, using those gates, one learns from tuples of data to infer something about worlds. The trick is a new form of loss function, a “contradiction loss,” that reconciles the logical value of all the neurons.
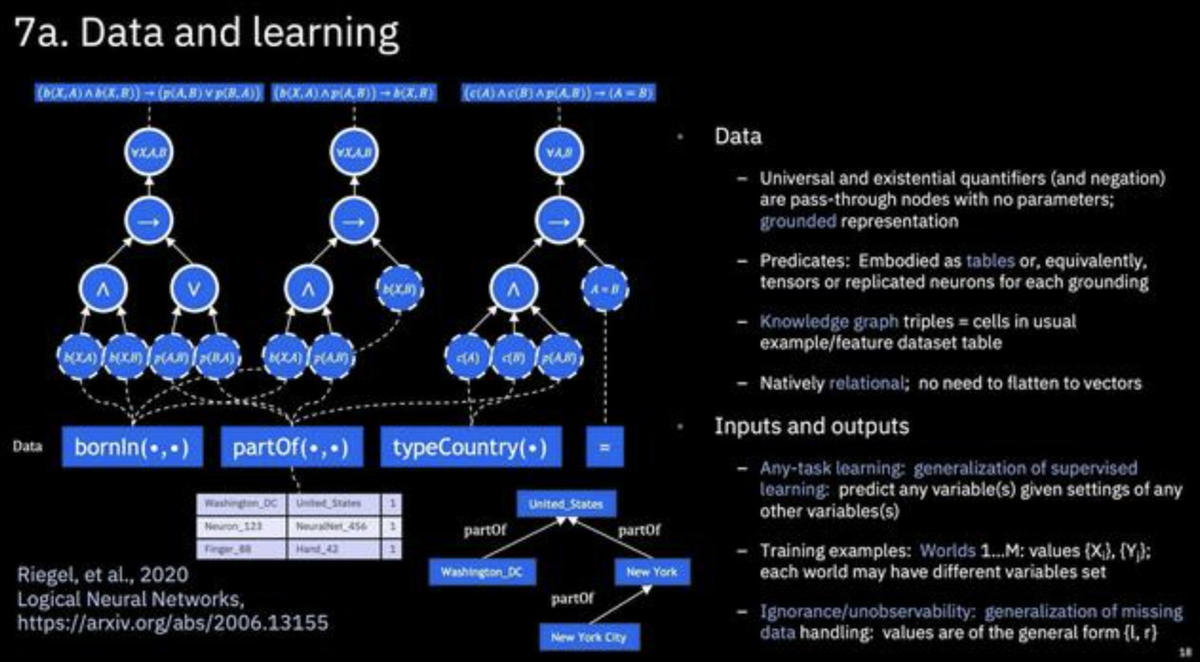
IBM researcher Alex Gray talked about how to merge traditional logic-gate neurons with differentiable neurons, as real-valued logic gates, to merge symbolic AI with deep learning to achieve neurosymbolic AI.
NeurIPS 2020.
There were some intriguing real-world applications of ML, including Google’s Loon unit discussing how to keep balloons stationary over the earth using reinforcement learning, and Australian startup QuantumBlack discussing how they optimize the “flight” of racing sailboats in the America’s Cup competition, also using reinforcement learning. They’re getting ready to use the techniques to race for the Cup next year.
Benevolent AI, a firm that develops ML for drug discovery, talked about how it helped to resuscitate an existing drug, Baricitinib, developed by the pharma firm Incyte, as a COVID-19 treatment. They constructed a knowledge graph of COVID-19 and all drug therapies and queried it using network analysis. The analysis proposed a possible COVID-19 match in Baricitinib, a treatment for rheumatoid arthritis that had already been approved a few years ago.
The drug has been able to reduce recovery time for patients in the hospital with COVID-19, and last month received an emergency-use authorization from the U.S. FDA. The discovery is not without controversy, as some doctors say its high cost — $1,500 per dose — outweighs its rather slender benefits.
Big pictures
The invited talks at the conference offered big-picture themes.
On Monday, professor Charles Isbell from Georgia Tech confronted the topic of bias in a thoughtful and imaginative way, leading the viewer through a tour of videos from multiple scholars reflecting on pitfalls in engineered systems. Isbell made the case bias is a core issue in ML, and computer science professor Michael Littman of Brown University helped him in the video by playing scrooge, acting as if there’s just nothing wrong with ML, everything’s fine.
Isbell’s point was that to embrace the need for rigor, machine learning scientists needed to stop being just “compile hackers” and instead become software engineers. The systems problem, said Isbell, is to not only make the systems accessible, including to non-programmers, but also to pursue inclusivity in the design of systems from the outset.
Isbell plans to release the videos of the fourteen participants in full, each an hour long, over the course of the next several months.

Professor Charles Isbell from Georgia Tech opened the conference Monday with a thoughtful and imaginative discussion of bias in machine learning. With the help of computer science professor Michael Littman of Brown University, playing Scrooge, who pretends not to believe bias is a real problem, Isbell led wove together videos from multiple scholars reflecting on pitfalls in engineered systems.
NeurIPS 2020
Jeff S. Shamma, incoming professor at University of Illinois at Urbana-Champaign, used his invited talk on Tuesday to discuss feedback control.
Feedback control refers to real-time decision-making in dynamic and uncertain environments, as Shamma defined it. Feedback control systems exist in equipment, such as an aircraft that must maintain a stable altitude. It can also be thought of more broadly as a feature of learning agents, said Shamma. Reinforcement learning is an example of how feedback can be used by a learning agent.
Shamma lead the audience to the point of describing a kind of robustness principle, how to know whether a learning rule for machine learning system would hold up under conditions of variability. Shamma’s talk made one reflect on the many layers of control in a system, from fine-grained to high-level, and how feedback is an element that becomes crucial for control.
One of the cautionary notions to come out of the talk is what’s called the “waterbed effect.” This is the broad observation that a consequence of any feedback loop is that as one thing gets better in a system, some other part of the system may get worse. It’s about trade-offs, in other words, and about limitations. The popular notion of “no free lunch” in learning theory is more or less a kind of waterbed effect, said Shamma. Another way of characterizing the waterbed effect was offered by Gunter Stein in the 1990s, called the “conservation of dirt.” You can only ever move dirt from one place to another. you can never get rid of it.
People working on systems may not want to always think about such limitations.
Shamma also had fascinating points to make about stability, how a system may asymptote into a range of behaviors. Stability in this way can be an interesting “modular” concept to use in ML, he suggested.

Jeff S. Shamma, incoming professor at University of Illinois at Urbana-Champaign, discussed feedback control. Shamma made reference to Gunter Stein’s observation in the 1990s, that for any optimization system, there’s always what’s called the “conservation of dirt.” You can only ever move dirt from one place to another, you can’t get rid of it.
NeurIPS 2020
Shamma’s parting thought was that the ways in which control interacts with learning is an expanding topic of study. “Today’s talk could have been alternatively titled, Reading the mind of a controls researcher and how they think about learning,” said Shamma.
Also Monday, a tutorial on reasoning brought together three complementary presentations by Francois Chollet and Christian Szegedy of Google, and Melanie Mitchell, the Davis Professor at the Santa Fe Institute.
Chollet made the case that abstraction is key to intelligence. You may recall that Chollet last year proposed a test of intelligence called the Abstraction and Reasoning Corpus.
Chollet approached his subject by discussing ways of thinking about generalization, meaning, the ability to convert past knowledge into a present ability to handle novel situations. True AI, if you will, would have a kind of extreme ability to generalize.
The opposite, he noted, is taking shortcuts, simply using more training data to optimize in a very narrow way on a given metric. That’s basically the problem of AI today: lots of skills optimization but no intelligence.
Abstraction, on the other hand, would be based on a kind of core knowledge, rather than experience. “Abstraction is the engine by which we produce generalization,” said Chollet. According to the kaleidoscope theory, abstraction is finding kernels that are reusable, and intelligence is a high degree of sensitivity to similarities. This borders on human intuition, he noted.
Deep learning is able to do some kinds of abstraction, as a geometric morphing between two domains, tracing a manifold. In that sense, said Chollet, generalization is the ability to interpolate between samples that are close together on the manifold.
The reverse is true, said Chollet, that when perturbations are injected to neural nets, the networks prove brittle, because they rely to much on geometric proximity of samples, rather than a topological structure that would be robust.
Chollet took exception to the deep learning pioneer Geoffrey Hinton, who is quoted as saying deep learning will be able to solve all intelligence problems. Deep learning, said Chollet, can’t move beyond problems of perception and measurement. In particular, it can’t do programmatic, or discrete generalization, where the sampling of the manifold is not dense.
For those challenges, Chollet suggested the approach was more like software development, the re-use of modules that come from a domain-specific language, meaning, a search through that language.
The road ahead, concluded Chollet, is to combine deep learning with that domain-specific search, combining value-centric abstraction/perception with programmatic abstraction, or Type I and Type II thinking, as in economist Daniel Kahneman’s “fast and slow thinking” paradigm.
“If you want to know how AI will operate in the future,” said Chollet, “I think you should just look at how human engineers operate today.”
“Engineers constantly abstract programs developed on a different task,” essentially reusing modules.
The bottom line, deep learning will reuse an inventory of priors, via a discrete search process guided by deep learning.
Battle for knowledge
The talks by Chollet and Mitchell and Szegedy were one kind of theoretical exploration; another was the all-hands workshop on knowledge representation that took place on Friday. It featured numerous heavy hitters, including deep learning skeptic Gary Marcus, his arch-nemesis, Yoshua Bengio of the MILA institute in Montreal, Kahneman, and Oren Etzioni of the Allen Institute, among others.
Etzioni presented a novel take on an old idea, John McCarthy’s AdviceTaker, proposed but never actually implemented by McCarthy. The program was supposed to submit axioms to a theorem prover and produce logical deductions. The updated paper uses a Transformer neural net in place of the theorem prover, so it does away with formal logic. A paper in more detail was featured at the conference.
Bengio focused on what’s called verbalizable knowledge, the concepts we can name with language. These are distinct from implicit knowledge, where machine learning spends most of its time. Verbalizing goes to the heart of the problem of generalizability, Bengio argued. Through language, humans are able to generalize to a novel distribution, such as understanding a science fiction story, observed Bengio.

Yoshua Bengio of Montreal’s MILA institute of AI gave a talk on he called verbalizable knowledge, the concepts we can name with language. These are distinct from implicit knowledge, where machine learning spends most of its time. Bengio argued for a fusion of deep learning with symbolic representations by having attention mechanisms operate on sparse graphs of concepts.
NeurIPS 2020
Bengio made the case for bridging the verbalizable by developing systems that would combine textual representations with visual representations, and explorations of an environment. Bengio referred to work on attention, including Transformers, and how they could operate over sparse factor graphs, where knowledge is formed of pieces of information that are disparate from one another.
A panel talk Friday afternoon within the workshop brought together Marcus, Bengio, and Kahneman with Luis Lamb, who is professor of computer science at the Universidade Federal do Rio Grande do Sul; and moderator Francesca Rossi, an IBM fellow and the global lead for ethical AI at IBM.
(Rossi was also the chair of the last in-person conference anyone can remember for AI this year, the AAAI conference that took place in New York in February right before the pandemic closed everything.)
The panelists gave introductory remarks of a few minutes. Marcus went first. He argued “scaling has failed,” citing OpenAI’s GPT-3 neural network. “It’s still superficial and unreliable,” he says, giving hilarious examples of GPT-3 failures. The world needs neuro-symbolic hybrids, advised Marcus.
Lamb discussed a theme he’s expressed in a recently released paper, the “third wave” of neuro-symbolic AI. He agreed with Marcus that there is a “tension between learning and reasoning.”
Bengio discussed connections between knowledge representation and other questions in deep learning. In particular, he brought up “modularization,” and abstract variables relating to agents and actions, and causality. This had echoes of Bengio’s stand-alone talk about the verbalizable.
Kahneman asked the question, “How would an AI convince me personally that it knows what it’s talking about?” He said he agreed with Marcus on a lot of things, but not on the mistakes of GPT-3 as an indicator a program doesn’t know what it’s talking about. Rather, what AI needs is “some kind of anchoring in experience,” as Bengio put it. Kahneman brought up the example of a blind person speaking about the beauty of nature.
“That person has no access to the beauty of nature, but you wouldn’t want to say they don’t know what they’re talking about,” said Kahneman.
“Some kind of anchoring in perception or action would be absolutely necessary, and GPT-3 doesn’t have that, and I don’t think it can convince us, or even another model that is more advanced, that it knows what it’s talking about.”
The was a little bit of a sequel to a face-off that Bengio and Marcus had on the MILA campus a year ago, when they held their first semi-debate style discussion of deep learning pros and cons. The duo are set to hold an actually follow-up next week, December 23rd, virtually, of course.
Note that Marcus also presented separately in another workshop Friday on the topic of baby minds, and what AI can learn from them.
Real-world breakthroughs
Some of the presentations during the week got into more applied areas of AI, such as a giant, day-long series of talks on Friday the 11th on the topic of climate change.
Christopher Bishop, who leads Microsoft’s research lab in Cambridge, U.K., gave the Posner talk on Wednesday. His title: “The Real AI Revolution.”
The real revolution, in this case, is the way software is created.
“With AI, we have the ability to produce software that gets into the hands of millions of people but where each person has a bespoke version,” Bishop said.
The discussion, however, was really about a collection of practical breakthroughs in different domains that used ML as a key ingredient, the transformations of technology.
One of those transformations is a radical new way of storing data: Holograms. It’s an old idea, said Bishop, that is finally coming of age. The display and the camera in smartphones have improved dramatically and are now good enough to revisit holographic storage. And ML is now capable of reading out the data.
Holographic storage works by shooting two laser beams at a block of lithium niobate crystal. Where the beams cross, they create an interference pattern that alters the electrical property in that section of the crystal, by moving electrons to a “meta-stable state.” That alteration is the representation of data trapped in the crystal.
To read the data, a laser is shot through the crystal and projects the interference pattern into a detector, and a convolutional neural network is used to determine a probability distribution of symbols from the pattern that lands on the detector.
Getting good read performance from the CNN is still a research endeavor, said Bishop. Techniques such as Bayesian optimization are being used to refine the read accuracy by exploring the parameter space. Bishop said the Cambridge laser lab is using “machine learning in the loop” to optimize the system.

Christopher Bishop, who leads Microsoft’s research lab in Cambridge, U.K., talked about progress in holographic storage. It’s an old idea, said Bishop, that is finally coming of age, thanks to the fact the display and the camera in smartphones have improved dramatically, and now deep learning, such as convolutional neural networks, can be used to efficiently read out the data trapped in the lithium niobate crystal.
NeurIPS 2020
On another practical front, Bishop described a medical project of his lab called InnerEye. The project is helping improve what’s called precision radiotherapy. Precision radiotherapy tries to destroy tumors by blasting them with radiation. To do so requires focusing the radiation in a tight area that avoids healthy tissue as much as possible. That has traditionally been developed by marking up scans of tissue by hand, indicating the boundaries of tumor and tissue.
Now, InnerEye is using 3-D convolutions, a U-Net, to automatically learn those boundaries as a segmentation map. An oncologist is still in the loop, editing the output of the U-Net. Using ML can cut the segmentation task from 73 minutes to five minutes. Bishop brought in a collaborator, Rajesh Jena at Addenbrooks Hospital, to talk about how the ML work is now entering live radiotherapy. Jena called the project a “real game changer” in reducing treatment from hours to minutes.
Bishop concluded saying “I’ve been in machine learning for thirty-five years and this is by far the most exciting time.”
Winning papers
Another big item of the week is the recognition of papers that stood out among the thousands of papers presented.
The conference awarded three papers: a paper on multi-agent systems by scholars Andrea Celli and colleagues at the University Politecnico in Milan and Gabriele Farina of Carnegie-Mellon; a paper on constructing a small approximation of a large data set, by Michael Dereziński and colleagues at UC Berkeley; and OpenAI’s paper this year on GPT-3.
As the NeurIPS judges explained their choice, the paper by Celli et al. “solves a long-standing open problem at the interface of game theory”; the paper by Dereziński should have wide impact on the very broad use of what’s called the Nystrōm method in ML; and the OpenAI paper “is a very surprising result that is expected to have substantial impact in the field, and that is likely to withstand the test of time.”
The papers be Celli et al. and Dereziński et al. were presented on Tuesday in a theory spotlight session; the GPT paper was presented Monday evening during a spotlight on language and audio applications.
The conference also gives an award each year to a paper from the past that has held up well. This year it was for a paper by Feng Niu and colleagues at U Wisconsin back in 2011 regarding stochastic gradient descent, the most commonly used form of optimization in ML today. The paper was the first to show how to perform stochastic gradient descent in parallel, to speed up optimization.
The authors gave a talk about the paper on Wednesday, during a session on approaches to optimization.
Niu is now a research scientist at Apple, along with co-author Christopher Ré.

