special feature
Managing AI and ML in the Enterprise
The AI and ML deployments are well underway, but for CXOs the biggest issue will be managing these initiatives, and figuring out where the data science team fits in and what algorithms to buy versus build.
Read More
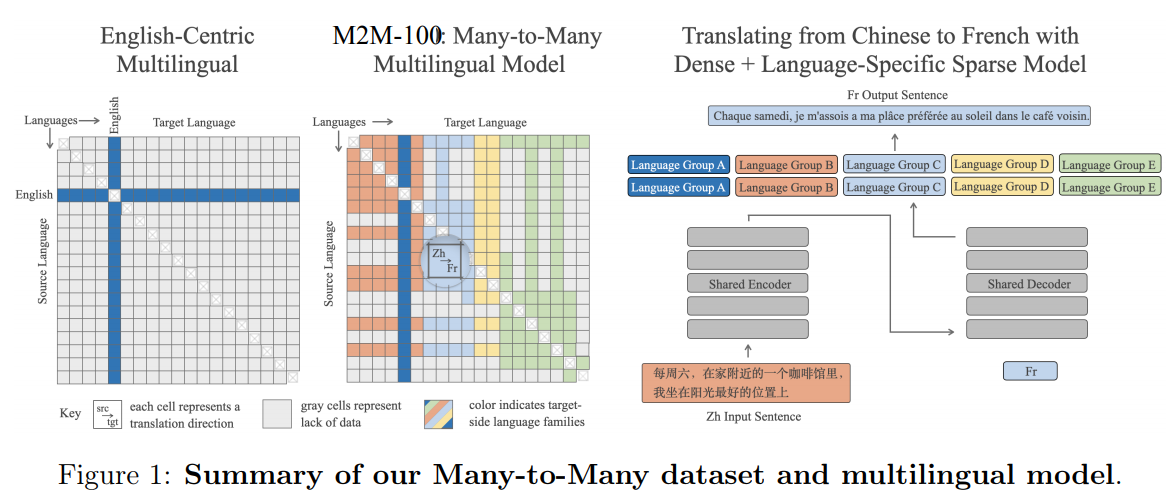
Facebook AI is open sourcing M2M-100, a multilingual machine translation model (MMT) that can translate any pair of 100 languages without relying on English.
The MMT is thought to be more accurate because it doesn’t have to use English as a go-between. Typically, models have been English-centric. So translating Chinese to French or Chinese to Spanish would require a translation into English before a final destination.
Facebook argues that direct translations between languages capture more meaning and outperform English-centric systems by 10 points on the BLEU metric.
Primers: What is AI? | What is machine learning? | What is deep learning? | What is artificial general intelligence?
M2M-100 is trained on 2,200 language directions. Facebook said it will also release the model, training and evaluation setup for M2M-100 for other researchers.
Facebook has been using machine translation across its network but building separate AI models for each language and task didn’t sale. After all, Facebook runs 20 billion translations every day on Facebook News Feed.

To train the MMT model, Facebook had to curates quality sentence pairs across multiple languages without English. There are more translations to English than direct between languages. Ultimately, Facebook built an MMT dataset of 7.5 billion sentence pairs across 100 languages. From there, Facebook narrowed pairs down to high quality and high data pairs. Statistically rare translation pairs were avoided.
Here’s a summary of the M2M-100 dataset and model.
![]()
Related:

