Just like us, robots can’t see through walls. Sometimes they need a little help to get where they’re going.
Engineers at Rice University have developed a method that allows humans to help robots “see” their environments and carry out tasks.
The strategy called Bayesian Learning IN the Dark—BLIND, for short—is a novel solution to the long-standing problem of motion planning for robots that work in environments where not everything is clearly visible all the time.
The study led by computer scientists Lydia Kavraki and Vaibhav Unhelkar and co-lead authors Carlos Quintero-Peña and Constantinos Chamzas of Rice’s George R. Brown School of Engineering was presented at the Institute of Electrical and Electronics Engineers’ International Conference on Robotics and Automation in late May.
The algorithm developed primarily by Quintero-Peña and Chamzas, both graduate students working with Kavraki, keeps a human in the loop to “augment robot perception and, importantly, prevent the execution of unsafe motion,” according to the study.
To do so, they combined Bayesian inverse reinforcement learning (by which a system learns from continually updated information and experience) with established motion planning techniques to assist robots that have “high degrees of freedom”—that is, a lot of moving parts.
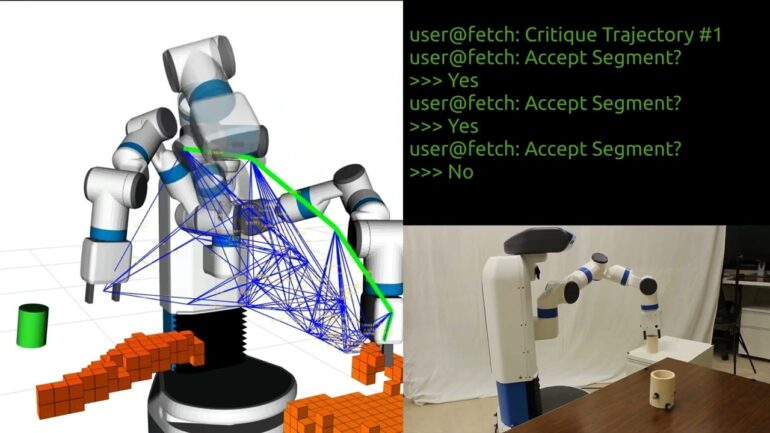
To test BLIND, the Rice lab directed a Fetch robot, an articulated arm with seven joints, to grab a small cylinder from a table and move it to another, but in doing so it had to move past a barrier.
“If you have more joints, instructions to the robot are complicated,” Quintero-Peña said. “If you’re directing a human, you can just say, ‘Lift up your hand.'”
But a robot’s programmers have to be specific about the movement of each joint at each point in its trajectory, especially when obstacles block the machine’s “view” of its target.
Rather than programming a trajectory up front, BLIND inserts a human mid-process to refine the choreographed options—or best guesses—suggested by the robot’s algorithm. “BLIND allows us to take information in the human’s head and compute our trajectories in this high-degree-of-freedom space,” Quintero-Peña said.
“We use a specific way of feedback called critique, basically a binary form of feedback where the human is given labels on pieces of the trajectory,” he said.
These labels appear as connected green dots that represent possible paths. As BLIND steps from dot to dot, the human approves or rejects each movement to refine the path, avoiding obstacles as efficiently as possible.
“It’s an easy interface for people to use, because we can say, ‘I like this’ or ‘I don’t like that,’ and the robot uses this information to plan,” Chamzas said. Once rewarded with an approved set of movements, the robot can carry out its task, he said.
“One of the most important things here is that human preferences are hard to describe with a mathematical formula,” Quintero-Peña said. “Our work simplifies human-robot relationships by incorporating human preferences. That’s how I think applications will get the most benefit from this work.”

“This work wonderfully exemplifies how a little, but targeted, human intervention can significantly enhance the capabilities of robots to execute complex tasks in environments where some parts are completely unknown to the robot but known to the human,” said Kavraki, a robotics pioneer whose resume includes advanced programming for NASA’s humanoid Robonaut aboard the International Space Station.
“It shows how methods for human-robot interaction, the topic of research of my colleague Professor Unhelkar, and automated planning pioneered for years at my laboratory can blend to deliver reliable solutions that also respect human preferences.”
More information:
Human-Guided Motion Planning in Partially Observable Environments
Citation:
Humans in the loop help robots find their way (2022, June 15)

