Roboticists worldwide have been trying to develop autonomous unmanned aerial vehicles (UAVs) that could be deployed during search and rescue missions or that could be used to map geographical areas and for source-seeking. To operate autonomously, however, drones should be able to move safely and efficiently in their environment.
In recent years, reinforcement learning (RL) algorithms have achieved highly promising results in enabling greater autonomy in robots. However, most existing RL techniques primarily focus on the algorithm’s design without considering its actual implications. As a result, when the algorithms are applied on real UAVs, their performance can be different or disappointing.
For instance, as many drones have limited onboard computing capabilities, RL algorithms trained in simulations can take longer to make predictions when they are applied on real robots. These longer computation times can make a UAV slower and less responsive, which could in turn affect the outcome of a mission or result in accidents and collisions.
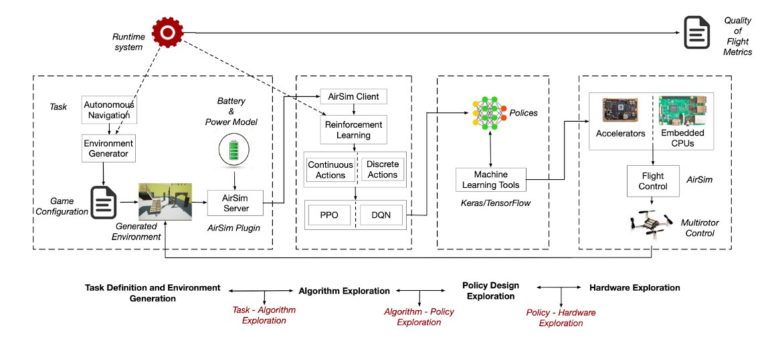
Researchers at Harvard University and Google Research recently developed Air Learning, an open-source simulator and gym environment where researchers can train RL algorithms for UAV navigation. This unique environment, introduced in a paper published in Springer Link’s Special Issue on Reinforcement Learning for Real Life, could help to improve the performance of autonomous UAVs in real-world settings.
“To achieve true autonomy in UAVs, there is a need to look at system-level aspects such as the choice of the onboard computer,” Srivatsan Krishnan, one of the researchers who carried out the study, told TechXplore. “Therefore, the primary objective of our study was to provide the foundational blocks that will allow researchers to evaluate these autonomy algorithms holistically.”
In Air Learning, UAV agents can be exposed to and trained on challenging navigation scenarios. More specifically, they can be trained on point-to-point obstacle avoidance tasks in three key environments, using two training techniques called deep Q networks (DQN) and proximal policy optimization (PPO) algorithms.
“Air Learning provides foundational building blocks to design and evaluate autonomy algorithms in a holistic fashion,” Krishnan said. “It provides OpenAI gym-compatible environment generators that will allow researchers to train several reinforcement learning algorithms and neural network-based policies.”
On the platform developed by Krishnan and his colleagues, researchers can assess the performance of the algorithms they developed under various quality-of-flight (QoF) metrics. For instance, they can assess the energy consumed by drones when using their algorithms, as well as their endurance and average trajectory length when utilizing resource-constrained hardware, such as a Raspberry Pi.
“Once their algorithms are designed, researchers can use the hardware-in-the-loop to plug in an embedded computer and evaluate how the autonomy algorithm performs as if it’s running on an actual UAV with that onboard computer,” Krishnan said. “Using these techniques, various system-level performance bottlenecks can be identified early on in the design process.”
When running tests on Air Learning, the researchers found that there usually is a discrepancy between predicted performances and the actual functioning of onboard computers. This discrepancy can affect the overall performance of UAVs, potentially affecting their deployment, mission outcomes and safety.
“Though we specifically focus on UAVs, we believe that the methodologies we used can be applied to other autonomous systems, such as self-driving cars,” Krishnan said. “Given these onboard computers are the brain of the autonomous systems, there is a lack of systematic methodology on how to design them. To design onboard computers efficiently, we first need to understand the performance bottlenecks, and Air Learning provides the foundational blocks to understand what the performance bottlenecks are.”
In the future, Air Learning could prove to be a valuable platform for the evaluation of RL algorithms designed to enable the autonomous operation of UAVs and other robotic systems. Krishnan and his colleagues are now using the platform they created to tackle a variety of research problems, ranging from the development of drones designed to complete specific missions to the creation of specialized onboard computers.
“Reinforcement learning is known to be notoriously slow to train,” Krishnan said. “People generally speed up RL training by throwing more computing resources, which can be expensive and lower entry barriers for many researchers. Our work QuaRL (Quantized reinforcement learning) uses quantization to speed up RL training and inference. We used Air Learning to show the real-world application of QuaRL in deploying larger RL policies on memory-constrained UAVs.”
Onboard computers act as the “brains” of autonomous systems, thus they should be able to efficiently run a variety of algorithms. Designing these computers, however, can be highly expensive and lacks a systematic design methodology. In their next studies, therefore, Krishnan and his colleagues also plan to explore how they could automate the design of onboard computers for autonomous UAVs, to lower their cost and maximize UAV performance.

“We already used Air Learning to train and test several navigation policies for different deployment scenarios,” Krishnan said. “In addition, as part of our research on autonomous applications, we created a fully autonomous UAV to seek light sources. The work used Air Learning to train and deploy a light-seeking policy to run on a tiny microcontroller-powered UAV.”
Progress in algorithms makes small, noisy quantum computers viable
More information:
Air learning: a deep reinforcement learning gym for autonomous aerial robot visual navigation. Machine Learning(2021). DOI: 10.1007/s10994-021-06006-6.
2021 Science X Network
Citation:
Air Learning: A gym environment to train deep reinforcement algorithms for aerial robot navigation (2021, August 16)
retrieved 17 August 2021
from https://techxplore.com/news/2021-08-air-gym-environment-deep-algorithms.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.

